编者按:如果用一个词来概括对于微服务的需求,那就是——速度。微服务的流行使得开发人员能够更高效地开发更多的功能,同时保证更可靠的性能,这种趋势已经彻底改变了开发人员创建软件的方式,而这种变化毫无疑问在软件管理(包括监控系统)中造成了涟漪效应。本文将集中讨论高效监控微服务所需的根本性改变并制定五项指导原则,希望能帮助读者采取最有效的监控方式来适应这种全新的软件架构。
监控是微服务的控制系统的关键部分,系统越复杂,就越难理解各个组件的性能状态并解决相应的问题。然而,在传统架构向微服务转变的过程中,鉴于软件交付的巨大变化,监控需要经历大规模的整顿才能在微服务环境中维持良好的表现。运用以下五项指导原则将帮助你在使用微服务时建立更有效的监控机制,应对与微服务相关的技术变化,以及调整相关的组织架构。
监控容器和其内部运行的内容
容器作为微服务架构中的重要组成部分,其意义近来逐渐凸显起来。
容器的速度,可移植性和隔离性优势让越来越多的开发人员能够轻松拥抱微服务模型。这些优势在许多书中都有所介绍,大家想必都了解一二,在此就不过多赘述了,你懂就好。
容器可以看作是大多数系统的黑盒子,这一点对于开发而言非常有用,因为从开发到生产,从笔记本电脑到云,容器发挥出了极高的可移植性。但是当涉及到一个服务的操作、监控和故障排除时,黑盒子反而让一些常见的操作更难进行,从而驱使我们想要了解:容器中到底运行着什么?应用程序/代码是如何执行的? 它可以监测到重要的自定义指标吗? 从DevOps的角度来看,我们不仅仅需要知道一些容器是存在的,更要深入了解容器内部的信息。
在非容器化的环境中那些仪表化的进程(比如在主机或VM用户空间中的Agent),对容器而言很可能无法很好的运行,因为容器更受益于小而独立的进程,并且需要保持尽可能少的依赖性。
而且,即使是规模适中的部署,运行数千个监控Agent也会消耗极其昂贵的资源,同时这也是编排的噩梦。容器有两个潜在的解决方案:1)请求开发人员直接对代码进行测试;2)利用通用的内核级测试方法来查看主机上的所有应用程序和容器的运行状态。针对这两种方式,我们不会在这里继续深入探讨,但每种方法都有其优缺点,关键需要适合于你的团队和服务。
利用编排系统提高服务性能
理解容器化环境中的运营数据是一个新的挑战。
相比所有组成功能或服务的容器所集合起来的信息,单个容器的指标具有更低的边际值。这类低边际值的数据尤其适用于应用程序级的信息,例如哪些查询的响应时间最慢,或者哪些URL出现的错误最多。同时它们也适用于基础架构级的监控,例如哪些服务的容器资源的使用超出了其分配的CPU份额等等 。
越来越多的软件部署需要编排系统将逻辑应用蓝图转换为物理的容器。 常见的编排系统包括Kubernetes,Mesosphere DC / OS和Docker Swarm。团队可以使用编排系统来(1)定义您的微服务(2)了解每个服务在部署中的当前状态。你可以认为编排系统比容器本身更为重要,因为容器本身的寿命是短暂的(它们只在存在的时间内有效),而你的服务对它们短暂生命周期的使用则至关重要。
DevOps团队应该重新去定义警报,从而专注于监控与服务体验相关的特征,因为这些警报是评估应用程序是否会受到影响的第一道防线。但是设定这些警报是极具挑战的工作,因为如果你的监控系统不是container-native属性,那就会变得异常困难。
Container-native的方案是利用业务流程的元数据动态聚合容器和应用的数据,并基于每个服务计算监控指标。 根据所使用的编排工具,可能需要设计不同的结构层级。例如,在Kubernetes中,通常会有一个Namespace,ReplicaSets,Pods和一些容器。 无论组成服务的容器的物理部署如何,在这些不同层级之间进行聚合对于逻辑故障排除而言至关重要。
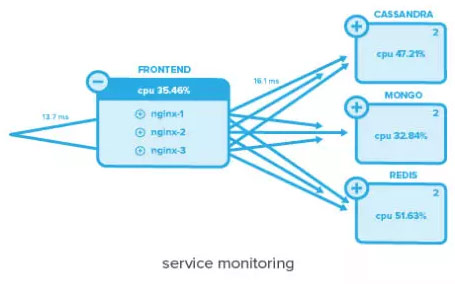
为弹性和跨环境的服务做好准备
弹性服务绝对不是一个新的概念,但是在容器环境中的变化速度比虚拟化环境快得多。而这种快速变化的环境会对脆弱的监测系统造成严重的破坏。
传统架构需要经常性地手动调整指标,并基于软件单独进行部署的检查。 这种调整可以具体地定义需要监控的各个指标,或者基于在特定容器中运行的应用进行配置。 虽然小规模的操作还算是可以接受的(比如几十个容器),但这种方式却无法承担任何更大规模的系统。而微服务的监控必须要能在弹性服务上进行自动扩容和缩容,而无需他人进行干预。
举个例子,如果DevOps团队需要靠手动定义一个容器来监控某个服务,那毫无疑问做了一个错误的决定,因为Kubernetes或Mesos会在一天内定期启动新容器。同样,如果在新代码构建并投入生产时需要运维人员安装自定义的stats point,这样在开发人员从Docker Registry中pull镜像的时候很可能会带来更多的挑战。
在生产环境中,实现跨数据中心或跨多个云的监控需要经过复杂的部署。利用单一的监控工具无法实现跨环境的监控,因此有必要部署一个监控系统来确保可以监测到不同环境中的服务,并且能够运维好动态的、容器化的IT环境。
监控API
在微服务环境下,API是一种通用的语言,同时API也是服务中唯一开放给其它团队的部分。从本质上来说,API的响应和一致性可以看作是一种“内部SLA”,尽管SLA并没有一个正规的定义。
因此,对API的监控是非常必要的。API监控可以用很多种形式来实现,但很明显不能仅仅局限于二进制检测。举例来说,以时间函数的方式来分析监控过程中频繁出现的端点就是一种非常有价值的方式,这样可以帮助团队在服务的使用过程中检测到是否有任何明显的变化,无论是因为设计的变化还是用户的变化。
与此同时,你还需要关注服务中那些最慢的端点,因为它们可能会暴露出系统中存在的严重问题,或者至少能帮你指出系统中最需要优化的地方。
跟踪系统中服务调用的能力也是另外一项重要的因素。当用户使用服务时,在基础设施的层面分解信息并从应用的角度审视环境一定可以帮助你形成对用户体验更加清晰而全面的认知。
“微服务化”你的组织架构
以上的建议都是聚焦于微服务和监控上技术的改变,下面重点说一下另一个重要的因素——人。
想必大家都熟知“康威定律”,它告诉我们团队的组织架构实质上决定了最终的系统设计,而正是对创造更快、更敏捷软件的需求,驱动着团队不断思考如何为了今后系统的发展去重组团队架构和管理规则。

所以,如果公司希望从一个新的软件架构当中获益,技术团队就必须像实现微服务化一样重建自我,这就意味着原先的团队要由更精简的团队组成并且彼此之间有着更松的耦合度,从而能够时刻面对相应的需求选择正确的方向。对于每个团队而言,他们可以更好地掌控所使用的语言、处理bug的方式、甚至是运维的职责。
基于这样的团队架构,DevOps团队可以像这样打造一个监控平台:允许每个微服务团队独立设立和管理警报、指标和仪表盘,从而从全局上监控整个系统的运维状态。
结语
是什么促使大家积极地向微服务转型?显而易见的因素就是——速度。企业希望用更少的时间为客户提供更具性能和价值的服务,因此为了保证速度,有必要引入更新的技术将架构向微服务转型并且将底层全面容器化,这也成为目前重要的发展趋势。
总而言之,微服务监控最基本的原则是需要去适应微服务所带来的底层技术和架构的改变,而运维团队需要更清晰地认识到这些变化,从而以更快速更简单的方式实现有效的微服务监控。

评论前必须登录!
注册