2016年对于网易杭州研究院(以下简称“杭研”)而言是重要的,成立十周年之际,杭研正式推出了网易云。“十年•杭研技术秀”系列文章,由杭研研发团队倾情奉献,为您展示杭研那些有用、有趣的技术实践经验,涵盖云计算、大前端、信息安全、运维、QA、大数据、人工智能等领域,涉及前沿的分布式、容器、深度学习等技术。正是这些宝贵的实践经验,造就了今天高品质的网易云产品。今天的转载来自网易杭州研究院运维团队,提出了一种模型化容器监控方案,并描述了该方案的主要实现方法。
近年来容器技术不断成熟并得到应用。Docker作为容器技术的一个代表,目前也在快速发展中,基于 Docker的各种应用也正在普及,与此同时 Docker对传统的运维体系也带来了冲击。我们在建设运维平台的过程中,也需要去面对和解决容器相关的问题。
Docker的运维是一个体系,而监控系统作为运维体系中重要组成部分,在 Docker运维过程中需要重点考虑。本文介绍了一种针对 Docker容器的自动化监控实现方法,旨在给 Docker运维体系的建立提供相关的解决方案。
容器
谈到容器,有人首先会想到 LXC(Linux Container)。它是一种内核虚拟化技术,是一种操作系统层次上的资源的虚拟化。在 Docker出现之前,就已经有一些公司在使用 LXC技术。容器技术的使用,大大提升了资源利用率,降低了成本。
直接使用 LXC稍显复杂,企业拥抱容器技术具有一定的门槛,可以说 Docker的出现改变了这一局面。Docker对容器底层的复杂技术做了一个封装,大大降低了使用复杂性,从而降低了使用容器技术的门槛。Docker给出了一些基本的规范和接口,用户只要熟悉 Docker的接口,就能够轻松玩转容器技术。可以说,Docker大大加快了容器技术的使用普及度,甚至被看做业界容器规范。
容器的监控
容器与通常的虚拟机在虚拟化程度上存在着差异,在监控手段上也有不同。一台虚拟机,我们可以当做一个物理机对待,而容器虽然也可以当做虚拟机,但这不符合容器的使用理念。在监控的实现过程中,我们更倾向于把容器看做是宿主机上的一系列进程树。
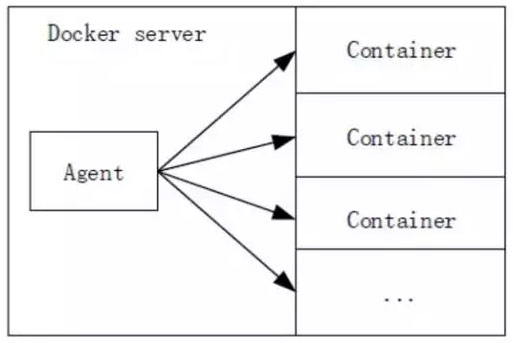
主流的监控系统实现过程中,一般需要在目标机器上部署 agent模块,通过 agent模块来做数据采集。而根据容器的使用理念,一般不建议在容器镜像里面捆绑 agent。当然这并不意味着数据没法采集,针对容器的虚拟化技术特点,在容器的宿主机上对容器进行数据采集是完全可行的,而且能够做到更加高效。
当然,如果把容器当做虚拟机对待,上面部署上 agent模块来采集监控数据,也是一种方法,但这不是推荐的做法。我们可以看到业界已经出现的一些 Docker监控方案,如 Docker Stats、CAdvisor、Scout等,也都是在宿主机上对容器进行监控的。本文提出的监控方案,也将会从宿主机上着手。
常见容器监控存在的问题
随着 Docker的应用,业界也出现了很多的监控工具,这些工具实际上也都能对 Docker容器进行一些监控。利用这些工具搭建一套监控系统来使用,也是基本能够解决一些需求的。但是分析这些监控工具,主要存在两方面的问题。
1. 与运维体系的结合度
这些工具基本都是独立的,很难与运维体系中其他系统整合打通。在运维自动化不断发展的今天,往往更加注重的是整个体系的集成度。所以需要有一个更好的模型化的思路,便于系统间的数据打通。
2. 监控的层次
这些工具的监控一般都只停留在单个容器的层面,例如对容器的 CPU,磁盘 IO等的监控。而大多数应用设计架构都具备一定的节点容错能力,单个节点的问题,往往不能够反映出应用的真实问题。所以监控需要覆盖到更多的层次。
模型化容器监控方案
这里我们从整体上提出一种模型化监控方案。这一方案有利于和运维基础的 CMDB系统打通,同时能兼顾到更多层次上的监控。
监控系统一般会涉及:数据采集、数据存储、数据分析和报警、数据展示等几个部分。本文将讲述一种模型化监控方法,主要提出了以下五种模型:
1、监控对象模型
这里我们将使用一种产品树的结构来建模监控对象。把监控对象分为四类,分别是产品、应用、集群、节点。
- 产品:一般是一个高层次的概念,一个产品一般可以独立输出,对外提供服务。
- 应用:是产品下的模块组成,多个应用共同形成一个产品。
- 集群:是应用的存在形式。同一个应用,一般会根据环境,地域等,部署多个集群。
- 节点:集群内承载服务的资源,包括前文提到的服务器,虚拟机,容器等。

这样,我们的监控数据采集,和视图展示,就可以基于产品树这个层次化的监控对象来做。每种监控对象上都可以有自定义的监控项,也可以继承上层的监控项。同时,分层次的监控对象,在很好地组织监控结构的时候,又可以从多种层次角度来反映出系统的运行状态和问题。
例如我们一个基于 Docker的应用需要监控,应用名称为 myDocker。我们可以建立如下监控模型:
- 产品:my_Docker_product
- 应用:my_Docker_app
- 集群:my_Docker_cluster
- 节点:my_Docker_container
2、采集器模型
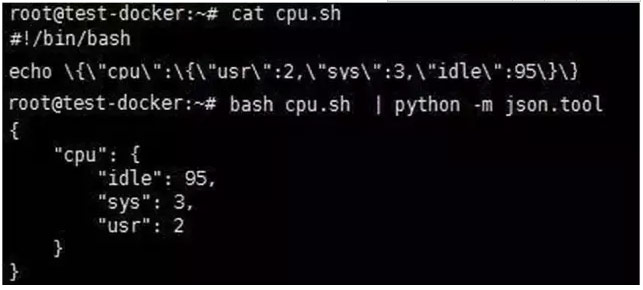
主要用于采集数据的模块,同时满足数据输出规范,为了便于解析,同时具备较好的数据结构展示,我们可以采用 Json格式作为数据规范。在数据的语义上需要匹配对应的数据模型。例如针对节点模型的采集器,可以是一个脚本,通过捕获脚本执行输出来获取相应数据模型的数据。而上层节点的采集器,则一般是基于节点数据模型的一些计算,这些计算一般包括 sum,avg,max,min等,一般反映的是整个集群下节点的一些聚合数据。
例如,一个简单的采集器模型如下:
3、数据模型
用来定义监控数据格式,模型包括数据项和指标项。一个数据项一般包含一个或者多个指标项。数据模型中的数据来自于对应的采集器。
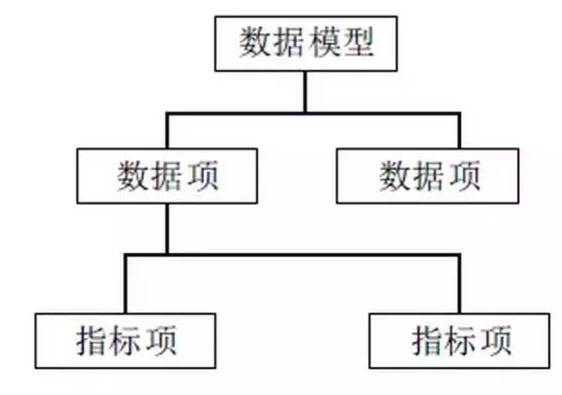
- 例如,针对 CPU可以监控如下模型:
- 数据项:cpu
- 指标项:usr,sys,idle
4、报警规则模型
在数据模型的基础上,针对每个数据指标项目,可以设置报警模型。例如,空闲 CPU少于 50%的时候触发报警,则可以建立如下规则:cpu.idle < 50
5、视图模型
这个模型将数据模型和视图关联起来了。包含数据展示方式定义,例如可以是趋势图,表格等。可以结合数据模型中的数据项与指标项,描述具体数据指标的视图展示方式。不同监控对象上的视图,一般都能从不同层次体现出监控。
用 XML格式描述视图模型如下:
<?xml version=”1.0″ encoding=”UTF-8″?>
<view id=”cpu” title=”CPU” type=”trend” modelName=”cpu”>
<dataItem function=”usr” as=”usr” />
<dataItem function=”sys” as=”sys” />
</view>
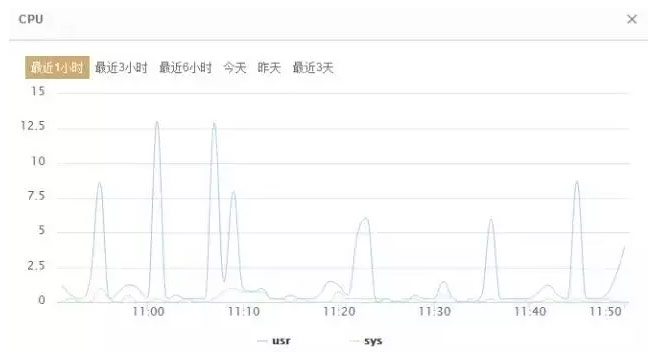
这个模型表示 CPU趋势图,且根据 usr,sys两个指标项画图。示例如下:
6、监控项模型
监控项模型,包含了采集器模型,数据模型,报警规则模型,视图模型等的组合。通过将监控项运用于监控对象上。从而可以对监控对象进行自定义模型化的监控。
容器监控整体架构
在模型完备后,整个监控项需要解决监控项下发,数据采集,数据分析报警,存储等问题。这里我们介绍一种分布式监控框架来将整个模型串通起来。
框架图示如下:
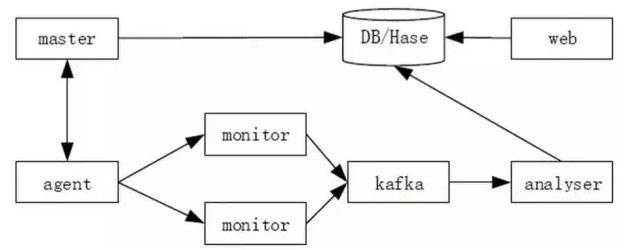
各模块的基本功能简要描述如下:
- agent:节点监控数据采集
- master:agent的管控中心,负责将监控项配置下发给agent。
- monitor:接收agent采集的监控数据,并统一存放到Kafka消息队列中。
- analyser:订阅Kafka对列消息,进行数据的分析处理,存储和报警。(实际实现过程中,可以视情况对该模块进行适度的功能扩展和模块拆分)
- web: 监控模型的各种管理,视图的展示。
- kafka: 消息队列,缓存采集数据,共其他模块订阅使用。
- DB/HBase:存储模型配置,监控数据等。
这个架构是一个常见的监控模型架构,而且比较容易和运维体系打通。在我们实现容器监控的过程中,就可以采用这个模型。
容器监控数据采集
数据采集是 Docker监控和一般监控系统实现过程中最有差异的地方。因为在 Docker容器内部,没有数据采集的 agent模块将不能直接依赖 agent来采集。
1. 节点数据
在容器宿主机上,我们可以获取到容器的很多基础数据。一般有以下几种方法。
通过 Docker命令
docker stats 这一方法比较简单,但是数据并不全面,我们可以看到如下效果。

基于 Linux文件系统
这个是比较推荐,且性能较好的数据采集方法。Linux的 /proc,/sys等系统目录下,记录了非常有用的监控数据。在这里,我们可以拿到大多数系统级,进程级别的运行数据,包括 CPU、磁盘 IO等。
例如我们要获取某个进程的 CPU占用,则可以采用以下方式计算出来。

2. 数据采集
集群的数据,是根据每个节点上的原始数据计算得到。是一种聚合运算,一般会有 sum,avg等运算场景。
3. 应用和产品数据
同理,应用和产品的数据则可以通过子节点的数据来计算得到。
监控的自动化
由于容器的自身特性,容器的销毁,创建等是一个很常见的场景。一个容器启动后,监控系统怎么察觉,同时需要对其做哪些数据模型的采集,这些问题就是监控自动化过程需要解决的。
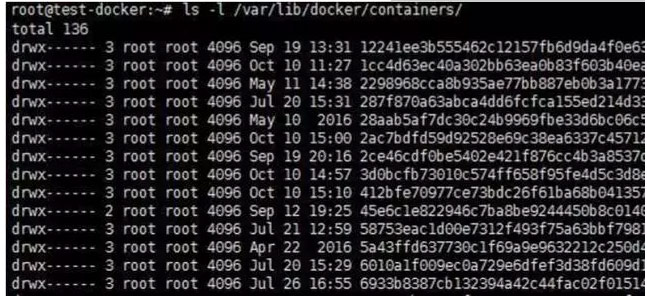
1. 容器的自发现
容器新创建,停止,或者销毁,在宿主机上可以感知到。一般可以从如下目录获取。由于 Docker安装配置不同,或者 Docker采用的文件系统的差异,可能部分目录会有不一致,但实际获取策略都类似。
2. 容器与监控对象的自动关联
容器作为节点,是需要关联到集群下面才能融入监控系统。这里我们可以采用镜像名称与集群名称的映射匹配来自动关联容器到集群。
通过如下容器目录下的配置文件,我们可以获取到容器的详情,其中包含的 Image即为容器所采用的镜像名称。
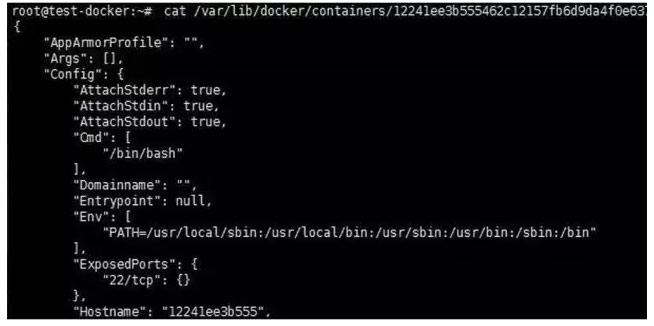
当容器关联到集群后,则可以自动监控项配置。通过 master将配置下发到容器宿主机上的 agent后,则可以开始对容器进行数据采集和上报,从而对容器进行自动监控。
总结
本文提出了一种模型化容器监控方案。通过对监控对象、监控过程进行建模,基于模型来驱动整个监控场景,同时描述了该方案的主要实现方法。
这套方案相比现有的容器监控实现,具有更好的灵活性和扩展性。通过模型的改进和扩展,能够方便地将 Docker容器的监控融入到现有的监控和运维体系中去。
监控系统本身是一个非常复杂的体系。本文描述的方案很多地方细节上还没有充分展开,模型的建立上可能也有一些局限和考虑不周的地方,需要后续逐步完善。希望本文思路能给读者在开发监控系统、建设运维体系的过程中提供一些参考。
——周宇
网易杭州研究院运维部

评论前必须登录!
注册