容器(Container)是近些年迅速火热的一门技术和话题,随着越来越多的公司开始在生产环境中使用容器,容器的重要性也越来越高。在 ECUG 十周年吴毅挺就容器过去的一些实践和经验带来演讲分享,以下是对他演讲内容的整理。

吴毅挺,携程系统研发部高级总监
2012 年加入携程,从零组建携程云平台团队,目前负责携程私有云、虚拟桌面云、网站应用持续交付等研发。
在线旅游与弹性需求
携程业务概况
近年来随着大众旅游消费的火热,携程的业务每年呈高速增长,2016年Q4财报显示携程2016年全年营业收入同比增长76%,交通票务营业收入同比增长98%,酒店预订营业收入同比增长56%,其他BU也有大幅增长,预计2018年携程的GMV将突破10000亿,并在2021年突破2万亿。我们开发的私有云和持续交付平台为携程超过 20 个 BU/SBU 服务,为了同步支撑业务的高速发展,我们也需要不断的技术革新,持续提升携程运营、研发的效率,缩短产品从idea到交付用户的时间。
节假日业务高峰
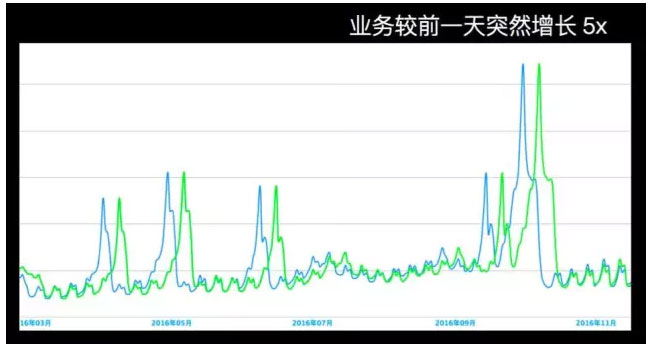
图 1
图 1 中可以明显的看到流量的起伏情况,旅游出行的特点是季节性的,在平时流量都比较低,但节假日前一天流量会突然增高很多。因此每到节假日就会面临成「倍」增长的扩容需求。在2016 年 12 月 26 日这一周,我们扩容了 1000 多台虚拟机。紧接着后一周,又扩容了 1000 多台。一般情况,临时扩容的需求较多,缩容会比较少,因为流量一上去之后,在短时间内不会下来,另外一方面,哪怕是流量下来了,由于以往资源申请没那么灵活,一般都会占用资源不释放,只能通过一些运维手段来监测资源使用情况然后告知业务部门去主动缩容。
携程目前大部分还是虚拟机,我们想缩短提前扩容的时间,以目前的虚拟机扩容方式,单个虚拟机扩容(从分配资源、调度、网络、os基础环境、应用部署等)至少是十分钟级别的,如果是每次扩容上千台的话,确实需要一定的时间,而且还得看看有无足够的资源,比如 1 月 1 日的流量提前一周就扩容好,但这不够灵活,业务流量下来以后需要缩容,目前的速度还是不够快。
针对这一场景,我们需要解决的问题是,能有更快的方案吗?如何能够做到更快速的弹性伸缩满足业务的需求?答案是利用容器。
再举个例子,携程有个深度学习的小诗机项目,将训练好的模型,对外提供服务,用户只要上传照片,后台的 AI 机器人就会根据照片中的内容自动写诗,这对于现行都市词穷一族来说,瞬间提升了意境,蛮有意思的。该项目希望在春节前上线,需要紧急扩容 1000 核,以满足春节期间大流量的需求,春节过后立马就可以缩容 90% 的资源。目前我们通过容器可以做到 1000 核的资源,5 分钟内完成 150 个容器实例的扩容,而且这还是 API 同步创建的速度,我们正在优化成异步的方式,相信后续提高并发能力后,速度还可以得到大大的提升。
其实携程的容器化已经进行一年多了,容器给我们最大的感觉是看起来简单,但要做好很难,原理不是很复杂,但是要利用这个技术做出一个产品或服务,中间有非常多的细节需要完善,比如如何做到用户体验更好的 UI 可视化、如何做到灰度发布、容器监控、容器基础镜像版本管理等等。
携程容器云定位
携程容器云定位有以下 4 点:
- 打造极致的秒级持续交付体验,服务 20+ BU
秒级意味着所有的扩容、缩容、回滚全部是秒级的,做到秒级是很难的,有很多需要突破的地方。比如,高速的镜像下发系统;高效的调度系统,稳定的容器服务,高度自动化的网络服务。
- 提升资源利用率
为了提高服务器资源利用率,我们采取账单的形式,督促业务线提高资源利用率,优化代码架构。我们对采集到的实时监控数据进行统计分析,按照 CPU、内存、存储、网络等多个纬度,按月计费,每个月会将账单发给业务线的 CTO。
- 组建服务化(mysql/kv/mq/…)or PaaS 化
应用所需要依赖的很多组件能够变成服务化,AWS 或者阿里云也做了很多这种服务。携程内部也在尝试把一些公共组件服务化,例如,MySQL,Redis,RabbitMQ 等。拿 MySQL 为例,我们让用户可以在测试环境快速部署 MySQL 实例,并且可以选择性的将测试数据灌入。新建的 MySQL 实例也会自动在数据访问中间件中完成注册,方便开发人员、测试人员快速搭建测试环境和测试数据。
- 从自动化到一定程度智能化
从自动化到一定程度智能化指的是基础设施变得更智能,比如能够具备一定的自我修复能力,如果是从上游到下游的一整套服务都具备智能化修复能力的话,这是一个非常大的突破,对于提升运营效率和故障恢复速度至关重要;
容器部署基本原则
- 单容器单应用
- 单容器单 IP,可路由的 IP
- 容器镜像发布
- immutable infrastructure
- 容器内部只运行 App,所有 agent 部署在 host 层面-包括监控/ES/salt等agent
以上是携程容器部署基本原则,看起来很容易,但确是携程经过很长时间的经验总结。
比如 单容器单应用这个原则,历史原因我们有混合部署的情况,单个vm部署多个应用,运维的复杂度会上升很多,比如:应用之间如何做到更好的资源隔离?发布如何避免相互之间的冲突?等等,使得我们的运维工具、发布工具变得格外复杂,开发、测试的持续交付效率也受到极大影响;
容器镜像发布也是我们做的一个比较大的突破,过去是代码编译成可发布的包,直接部署到vm内部,而现在是编译时直接生成容器的镜像,不同环境其实部署的是同一个镜像,并且不允许部署之后单独登陆进行配置修改,通过这种方式做到 immutable infrastructure ,保证开发、测试、生产环境的一致性,同时也保障了自动化扩容、缩容快速高效的进行。
是否在容器内部也运行各种运维agent 也是我们经过实践确定下来的;我们希望容器尽量简单,尽可能只包含运行的应用本身,此外将所有的agent合并到host层面,也能在很大程度上提升服务器资源利用率,agent数量下降一到两个数量级;但配套的管理工具(eg: salt) 需要做一次升级改造才能适配新的模式;
容器编排选型 & 取舍
OpenStack
携程除了容器之外的东西都是用 OpenStack 来管理的,OpenStack 可以用一个模块(nova-docker)来管理容器,携程在OpenStack方面有多年的二次开发技术积累、也大规模的部署运维经验,但最终没有选用 OpenStack,因为 OpenStack 整体过于复杂,调度效率也比较低,API 调度是 10 秒以上,可以进行优化,但我们觉得优化代价太大,OpenStack整体的复杂度也很高;
我们早期的胖容器(把容器当vm来使用,做代码包发布)的确是用OpenStack来做的,原因是我们希望把注意力放在容器本身,以最低的代价将容器先用起来,积累开发、运维经验;而到了瘦容器阶段(基于容器镜像做发布),我们发现OpenStack整体的设计理念从本质上讲还是为虚拟机隔离粒度的虚拟化方案设计的,而容器本身与vm其实差别很大,玩法也相去甚远, 于是我们对Mesos/K8s进行评估;
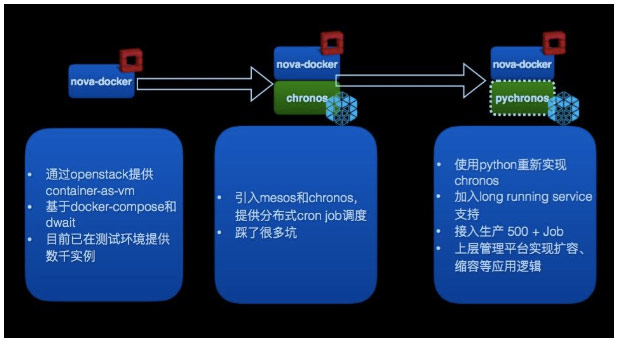
回顾我们的容器调度探索之旅,基本上可以用以下三个阶段来总结:
第一阶段,需要最快的使用起来,用最熟悉的技术来解决部署和调度。到了第二阶段有新的需求,引入 mesos 和 chronos,提供分布式 cron job 调度。第三阶段是使用 Python 重新实现 chronos, 并且单独实现了CExecutor等组件。
K8S
K8S 有很多很先进的设计理念,比如有 replication controller/Pod/Yaml 配置管理等,但这些理念在携程都很难落地,因为跟现有的运维模式、发布流程有较大的冲突。而且当前还缺乏大规模部署案例,网络尚无比较成熟的方案, 例如 L4/L7 负载均衡; 而在携程L4/L7服务已经比较成熟稳定, 并且与我们现有的发布系统Tars集成得非常好;
Mesos
Mesos 和 K8S 解决问题的思路是不一样的,基于 Mesos 我们可以非常容易的开发出适合我们场景的调度框架,并且非常容易和我们现有的运维基础服务对接集成;包括 L4/L7 负载均衡、发布系统等;
容器网络选型
- Neutron+OVS+VLan
-DPDK
-https 硬件加速
-单容器单IP,可路由 - vxlan+SDN controller
-vxlan offload TOR解封装
Neutron+OVS+VLan,这个模式非常稳定,对于网络管理也是非常的透明的。这也是携程的选择,现在的网络无论是胖容器还是容器轻量发布都用这种模式。我们也在测试 DPDK 和 https 硬件加速的效果。
我们也评估过类似flannel的网络,要求每个物理机独立网段,通过这个特性来做路由;非常不灵活的一点是容器如果迁移到另外一台物理机就需要换IP,无法满足我们的需求;
接下来会走 vxlan+ 基于BGP EVPN协议自研轻量级SDN controller的路线,vxlan offload TOR 解封装提高性能;对于openstack可见的还是大二层网络(vlan), 而实际上是通过underlay的三层路由进行转发;openstack与我们的控制器能实现元数据的一致性;关于这块,后续我们也会有相应的分享单独进行探讨;
如何配置容器网络
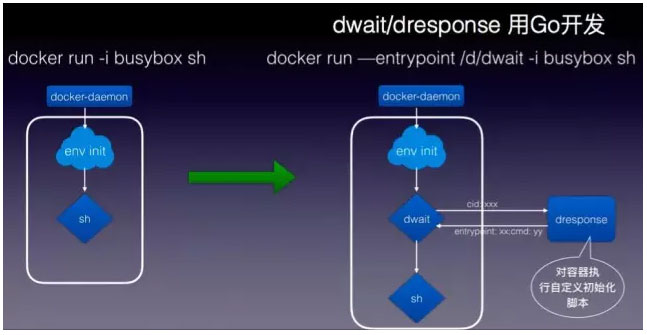
图 5
如图 5 用 dwait 和 dresponse,基于 Go 开发,dwait 会通过 unix socket 请求外部服务dresponse 做容器的初始化。当这个容器起来的时候,它的网络没有那么独立,在 Docker 里面是需要依赖外部提供信息的,所以需要知道哪个网段或者说创建的 neutron port 再配置到 Docker 容器内。这样做后就不会有网络丢失的情况。
Docker遇到的问题
接下来分享一下我们碰到的一些比较经典的Docker/Mesos相关的问题
Docker Issue

图 6
在我们尝试使用 Chronos 跑 cronjob 时,由于我们的 Job 执行频率非常高,导致物理机上出现非常频繁地容器创建和销毁,容器的创建和销毁比单个进程的创建和销毁代价大,会产生很多次内核的调用,磁盘的分配销毁,这对内核是一个非常大的压力考验。我们在实际操作过程中就遇到了一个 bug,如图 6 这台机器逐步失去响应,产生了 kernel soft lockup,慢慢的导致所有进程都死锁了,最终物理机重启了。为了避免频繁创建销毁容器,我们没有在 Chronos这种一个 task 一个容器的路上继续走下去,我们自己研发了 mesos framework,改成了一个Job,一个容器的调度方式。
Mesos Issue
- running的容器数量较多以后,无法再启动新的容器
- -kernel.keys.root_maxkeys debian default 200,centos default 1M
- mesos docker inspect 执行低效,尤其是单机容器数量大
- MESOS_GC_DELAY:6h 20K->1h
- MESOS_DOCKER_REMOVE_DELAY 1m
- docker force pull false
- API 性能差,功能不完善,获取异步 event 困难
- overall,很稳定,调度性能足够
Mesos Issue 性能很稳定,基本上不需要修改 Mesos 代码,只需要在我们自己写的Framework进行控制调度,控制如何启动容器。
CExecutor

图 7
- 自定义 CExecutor,Go 语言实现
-避免过于频繁创建删除容器,带来的副作用
– cpu load 高而且抖动很大
– 频繁启停容器引发的 docker 和 kernel 的 bug - task:container
-1:1->N:1 - 容器持久化
如图 7,可以观察得到前段抖动非常厉害(如果过渡频繁地创建删除容器,会带来非常大的负担,抖动会非常高),在用 1:1 调度之后就变得平缓了。所以携程自定义 CExecutorr(Go 语言实现),避免过于频繁创建删除容器,带来的副作用(抖动非常强、load 非常高),之后就基本上处于水平线了。
监控方案
Mesos 监控
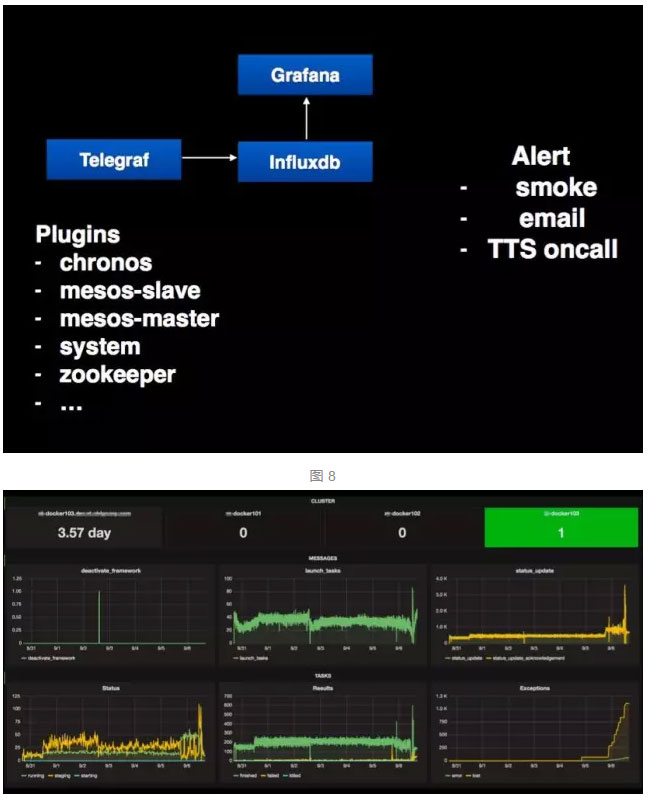
图 9
如图 8-9 携程用了很多开源技术,Telegraf、influxdb、Grafana 并做了一些扩展来实现mesos集群的监控,采集mesos-master状态、task执行数量、executor状态等等,以便当mesos集群出现问题时能第一时间知道整个集群状态,进而进行修复,此外, 我们还从mesos调度入手,做了一些应用层的监控,比如: 针对cron job类型的应用,让用户可以看到 job 应该在什么时候执行,执行的过程,整个 job 的成功率,job 还有多个实例在跑等;
容器监控
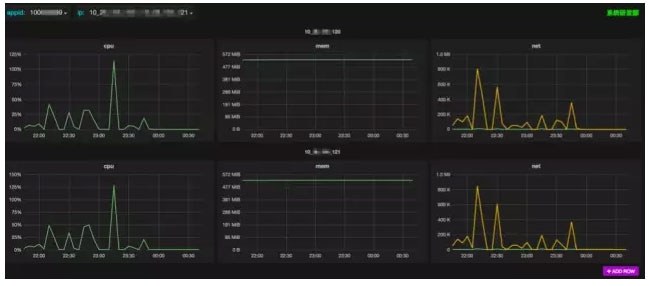
图 10
携程监控团队全新开发了一套监控系统hickwall(http://2016.qconshanghai.com/speakers/202127),也实现了对容器的监控支持;hickwall agent部署在容器物理机上,通过docker client 、cgroup等采集容器的运行情况,包括 CPU 、Memory、Disk IO等常规监控项;由于容器镜像发布会非常频繁的创建、删除容器,因此我们把容器的监控也做成自动发现,由hickwall agent发现到新的容器,分析容器的label信息(比如: appid、版本等)来实现自动注册监控;在单个容器监控的基础上,还可以按照应用集群来聚合显示整个集群的监控信息;
除此之外,携程还做了各个业务订单量的监控,比如说今天有多少出票量、酒店间夜数,而我们可以非常精准地根据历史的信息预测未来的数据,比如说明天的这个时间点订单量应该在多少、准确性在 95% 以上,一旦比预估的偏差太大的话,就会告警有异常,它把一个综合的业务运行健康度提供给业务研发团队,而不仅仅是单个容器的运行情况。
我们在线也会做一些压测,比如说这个集群下面有 10 台机器,这 10 台机器的负载均衡权重都是 0.1,我们会把其中一台调高,看它的吞吐和响应的情况。测出它到了一定极限能提供的QPS,就可以知道这个集群还剩多少性能高容量,这个容量就是这个集群还能承载多大的压力,比如说有 25% 的富余,根据订单的变化就可以知道还多多少或者还缺多少,这样就能做到更好的扩缩容调度;目前基于vm的应用已经能基于容量规划和预测实现自动扩容,后续容器的扩缩容也会接入,并且做到更实时的扩容和缩容调度;
此外,容器监控对于携程创新工场的团队是很有意义的,这些新孵化的BU对成本控制更严格,随着容器上线,我们能为其提供性价比更高的基础设施。
CDOS Overview
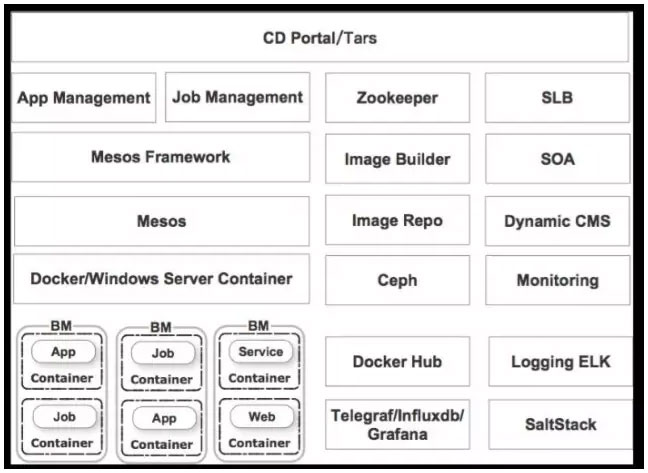
图 11
CDOS 全称是 Ctrip Data Center Operating System, 我们希望通过CDOS来调度多个数据中心的资源,就好比一个操作系统调度各种资源给各个进程一样,CDOS会调度多个数据中心的计算、网络、存储的资源给到不同的应用,满足各个应用所需的冗余度,并且会动态的维持这个冗余度,一旦出现异常,可以自动尝试修复,删除出现问题的容器实例,并部署新的实例;这里面会涉及到非常多的模块。
如图 11 最上层是持续交付的发布系统,这一层是跟应用交付相关的东西,开发人员、测试人员都会用的发布系统。下面是针对不同运行模式的应用定制的两套调度管理模块,一个是cron Job,另一个是long running service;两者在管理、部署、发布方面都有一些差异化;
底层资源分配是用Mesos 来实现,历史原因,我们还有大量的服务部署在windows上, 因而需要同时支持windows server container 和 docker。长期来看未必是继续使用 Docker,因为 Docker 太激进了,目前已经有多种container实现方式可以选择。Windows 容器方面携程也已经做了一些POC,实现类似前面提到的ovs + vlan的网络接入,遵循单容器单ip等原则,并且投入覆盖了部分的测试环境。
图中右边有很多服务,比如L4/L7负载均衡、 SOA 的服务,CMS应用元数据管理、监控、日志收集、镜像管理和推送等模块;由于我们采用容器镜像发布,要实现秒级交付,对于镜像推送速度有很高的要求,当base image没有变化时,只需要把应用新版本build出来的app层通过我们开发的Ceph同步模块推送的多个数据中心;当base image也变更时,情况会更复杂,除了同步到各个数据中心的Ceph对象存储,还需要预先下发到可能用到的Docker服务器,才能以最快的方式启动容器;
以上就是携程容器云的概况介绍,未来我们还会针对一些模块做专题分享(eg, 容器监控、pychronos调度、SDN、镜像管理等等),欢迎大家一起来交流和探讨;
业界普遍看好 Docker 容器云的前景,但是也不乏一些唱衰的观点出现。对构建一个良性的社区环境而言,正面和反面的声音同样重要。机会与挑战并存,让我们一起期待容器云未来的发展。

评论前必须登录!
注册