“在你考虑选择一个供应商之前,下载Essential Cloud Buyer’s Guide 学习,这是个决定性因素,而且可以帮助你为你的基础设施需要做最好的选择,采用Internap。”这是来自迄今为止最大的Docker Swarm集群组织Swarm3k的领袖人物Chanwit Kaewkasi教授的介绍。
回顾Swarm3K
Swarm3K是第二个合作性项目试图建立一个大规模Swarm模式的docker集群。发生在2016.10.28,超过50名个人及公司加入这个项目。
Sematext是最早的公司之一,提出以提供他们的Docker monitoring and logging 解决方案来帮助我们。他们变成Swarm3K的官方监控系统。Stefan,otis和他们的团队从一开始就提供了出色的支持。
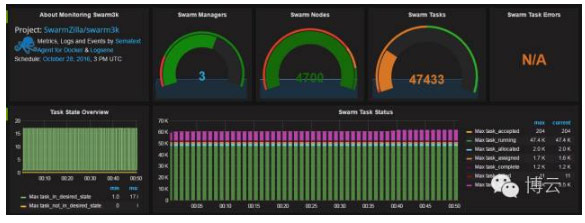
Swarm3K公开数据仪表by Sematext
据我所知,随着此刻docker成为全球性服务,Sematest是唯一的允许部署监控代理docker监控公司。这种部署模式提供非常简化的部署流程。
Swarm3K设置和工作负载
这里有2个计划好的工作负载:
- MySQL with WordPress cluster
- C1M
25个节点构成一个MySQL集群。我们经历了一些混合ip地址来自我的网络和进入网络。在过去,同样的问题在形成一个Apache Spark集群时被发现(参考 https://github.com/docker/docker/issues/24637)。我们通过绑定集群到一个覆盖网络来避免这个问题。
在我们巨大的集群调度一个WordPress节点,并且我们故意不去控制它。当我们试图链接一个WordPress节点到MySQL集群后端时,链接超时。我们推断一个WordPress/ MySQL结合体会被设置正确的运行,如果我们把他们一起放在同样的DC中。
我们以3000个节点为目标,但是最后我们成功的形成了一个工作的、地理上分布的4700个节点Docker Swarm集群。
Swarm3K观察
我们还从这个问题中学到,覆盖网络的性能很大程度上依赖在每个主机上正确的网络配置协调。
当MySQL/WordPress测试失败,我们改变了方案,在路由网络上试用NGINX。
进入网络是一个支持64k IP地址的/16网络。建议通过Alex Ellis,我们于是在构建集群上开始4000个NGINX容器。通过测试,节点仍断断续续。NGINX服务开始同时构建路由网络。他可以正确的服务尽管某些节点保存失败。
我们结论是路由网络1.12稳如磐石并且为生产做好了准备。
我们停止了NGINX服务并且开始测试尽可能多的容器调度。
这一次我们仅用“高山”当做我们为Swarm2K做的。无论如何,调度率非常低。我们大约在30分钟内准备做47000个容器。因此它是需要~10.6个小时用1M容器填充集群。不幸的是,因为它用时太长,当它没有更进一步时我们决定关闭管理。
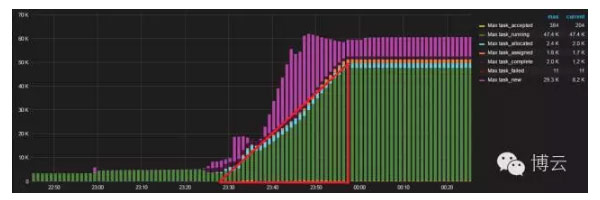
Swarm3k任务状态
调度一批大型的容器让集群有压力。我们计划推出大量容器使用“docker scale alpine=70000”。创建了一个大型调度队列,直到所有70000个已完成调度的容器将不会提交。这就是为什么当我们关闭管理所有调度任务消失并且集群变得不稳定,Raft日志损坏。
最有趣的一件事就是我们能够收集到足够的CPU配置信息来告诉我们是什么让集群保持忙碌。
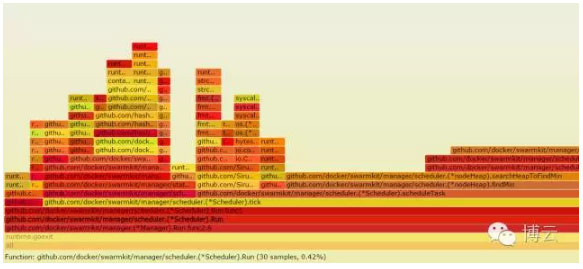
我们能看到只有0.42%的CPU是花费在调度算法。我想我们可以确定的说:
Docker swarm1.12版在调度算法上是很快的。
这意味着有机会引入一个更复杂的调度算法,可以提高资源利用率。
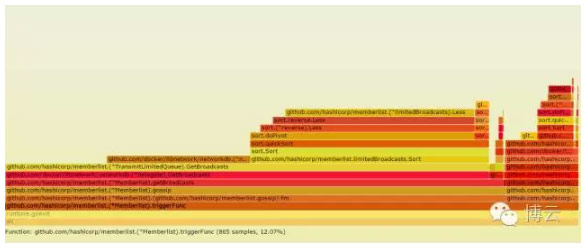
我们发现大量的CPU周期使用在了节点通信。我们能看到Libnetwork的成员列表的内层。它使用了~12%的CPU。
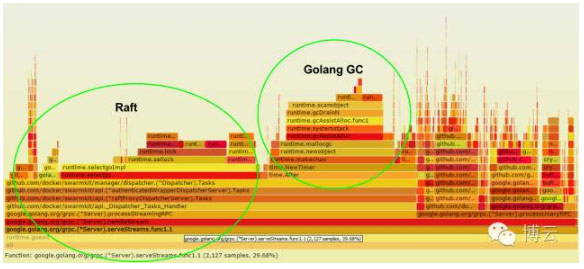
其他主要CPU消费是Raft通信,其还导致了GC。这使用了~30%的CPU。
Docker Swarm经验教训
这里总结了几点我们一起学习到的经验:
- 像这样的一个大型节点集合,管理员需要很多处理器。无论何时Raft恢复处理生效,处理器都会阻止。
- 如果先前的管理失败,最好在那个节点上停止“docker daemon”并且等待直到集群与n-1管理再次变得稳定。
- 在生产中别使用“docker-D”。当然,你知道你不会那么做的。
- 保持保留快照越小越好。Docker Swarm默认的配置会这么做。坚持Raft快照使用另外的CPU。
- 管理上千的节点需要庞大的资源,无论是CPU还是网络带宽。相比之下,几百几千的任务需要高端内存节点。
- 推荐500-1000个节点用来生产。我猜在大部分情况下你不需要比这更大节点,除非你正打算下一个Twitter。
- 如果管理员似乎被卡住了,等吧。他们最终会恢复。
- 指标参数-通知-地址 强制为路由网工作。
- 把你的运算节点尽可能的接近你的数据节点。覆盖网络为所有主机工作最佳而将调整Linux网络配置。
- 尽管调度缓慢,Docker Swarm模式是稳固的。这次没有任务失败即使和变化莫测的网络连接着大型集群。
关于作者
最后,我想感谢所有的Swarm3K的英雄:@FlorianHeigl, @jmaitrehenry来自 PetalMD, @everett_toews来自 Rackspace, Internet Thailand, @squeaky_pl, @neverlock, @tomwillfixit from Demonware, @sujaypillai来自 Jabil, @pilgrimstack来自OVH, @ajeetsraina来自Collabnix, @AorJoaand @PNgoenthai来自Aiyara Cluster, @f_soppelsa, @GroupSprint3r, @toughIQ, @mrnonaki, @zinuzoid来自HotelQuickly, @_EthanHunt_, @packethost来自Packet.io, @ContainerizeT – ContainerizeThis The Conference, @_pascalandy from FirePress, @lucjuggery来自TRAXxs, @alexellisuk, @svega from Huli, @BretFisher, @voodootikigod来自 Emerging Technology Advisors, @AlexPostID, @gianarb来自ThumpFlow, @Rucknar, @lherrerabenitez, @abhisak来自 Nipa Technology, and @enlamp来自NexwayGroup.
我想再次感谢Sematext最棒的课程Docker monitoring 系统,DigitalOcean提供所有的资源给大型Docker Swarm管理员,Docker开发团队创造了这个伟大的软件和并在运行中支持我们。
此时此刻我们没有设法让我们想要的150000个容器起动,我们设法创造一个接近5000节点的Docker Swarm集群分散在几个大陆。我们从课程中学到的经验会帮助我们在接下来的几年起动其他大型Docker Swarm集群。谢谢大家,我期待着新的路程。
相关文献:Getting Started With Docker(https://dzone.com/refcardz/getting-started-with-docker-1)
现在用MongoDB开始比以往更加简单了,数据库允许初创公司和企业快速构建发展应用。推荐MongoDB Atlas,the official hosted service for the database on AWS.现在就试试吧!采用MongoDB。
原文:Docker Swarm Lessons from Swarm3K
作者:Chanwit Kaewkasi
翻译:袁思思
来源:DZone
原文链接:https://dzone.com/articles/docker-swarm-lessons-from-swarm3k

评论前必须登录!
注册