为了满足渲染、基因测序等计算密集型服务的需求,UCloud 推出了“计算工厂”产品,让用户可以快速创建大量的计算资源(虚拟机)。该产品的背后,是一套基于 Mesos 的计算资源管理系统。本文简要介绍该系统的结构、Mesos 在UCloud 的使用、解决方案以及遇到的问题。
业务需求
需求主要是两方面:
- 同时支持虚拟机和容器。在“容器化”的浪潮下,为什么我们还需要支持虚拟机呢?首先,一些业务有严格的安全隔离要求,容器虽好,但还做不到和虚拟机同等级的隔离性。其次,一些业务程序不能运行在 Linux 上,比如图片、动画的渲染软件大都是 Windows 程序。
- 整合多地域多数据中心。我们的资源来源于一些拥有闲置资源的合作伙伴,这些资源散布于多个地域的多个数据中心中。我们的平台需要能够支持全局的调度,同时尽可能减小运营、运维的成本。
简单地说,我们需要有一个平台,统一封装多个数据中心的计算资源,并且同时支持虚拟机、容器等多种形式的资源使用方式。
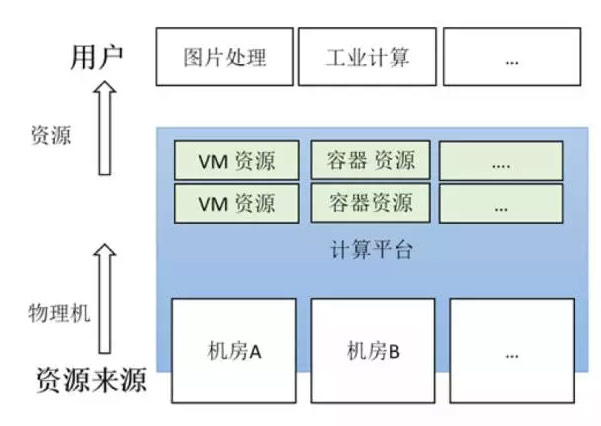
图1:计算资源管理平台的需求示意图
为什么选择 Mesos
Mesos是Apache下的开源分布式资源管理框架,它是一个分布式系统的内核。
通过 Mesos,一个数据中心所提供的不再是一台台服务器,而是一份份的资源。资源可以是 CPU 核数、内存、存储、GPU 等等。如果把一个数据中心当做一个操作系统的话,Mesos 就是这个操作系统的内核。
我们选择 Mesos 的原因在于它拥有高度可扩展性,同时又足够简单。
作为内核,Mesos 只提供最基础的功能:资源管理、任务管理、调度等。并且每一种功能,都以模块的方式实现,方便进行定制。架构上,Master 和 Agent 两个模块就实现了资源相关的所有工作,用户只需根据自己的业务逻辑实现 Framework 和 Executor 即可。这样就支持我们能够把计算资源封装成虚拟机、容器等各种形式。
采用 Mesos 来进行容器编排的方案已经被很多厂商使用,相关的资料文档也比较丰富。然而用 Mesos 来管理虚拟机,业内很少有这方面的实践。本文的余下内容,主要向读者分享一下 UCloud 用 Mesos 管理虚拟机的思路和实践经验。
Mesos 简介
Mesos 采用 Master-Agent 架构。Master 负责整体资源的调度并对外提供 API。Agent 部署在所有机器上,负责调用 Executor 执行任务、向 Master 汇报状态等。
Mesos 提供了一个双层调度模型:
- Master 在 Framework 之间进行资源调度。
- 每个 Framework 内部实现各自业务的资源调度。
整体架构如下图:

图2:Mesos 的双层调度结构图
架构设计
整体架构
在 Mesos 的双层调度模型上,平台的整体架构如下图:
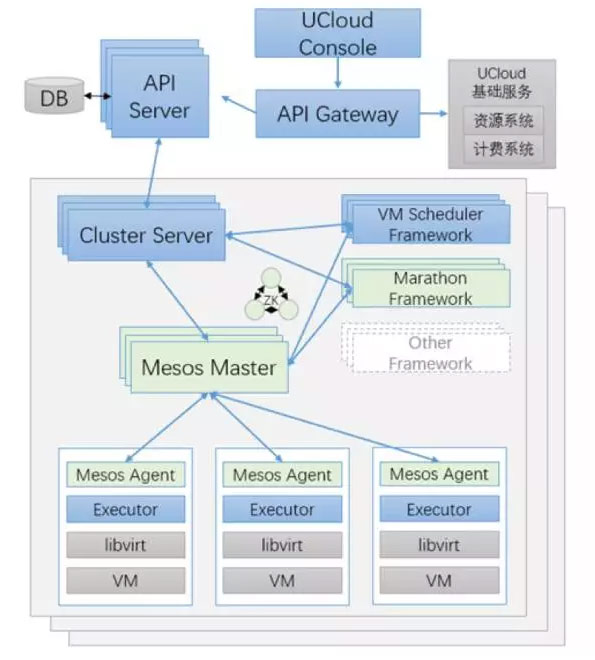
图3:基于Mesos的资源管理平台整体架构图
结构如下:
- 每个 IDC 一套或多套 Mesos 集群;
- 每个 Mesos 集群一个 Cluster Server,与 Mesos Master 以及 Framework 交互,负责集群内部的调度、状态收集和任务下发
- 一个Mesos集群上有多个Framework,一个 Framework 负责一种业务,比如 VM Scheduler 管理虚拟机,Marathon Framework 管理Docker任务
- VM Framework框架实现管理的 Excutor 基于Libvirt,实现虚拟机的创建,重启,删除等操作
- 所有 Cluster Server 统一向 API Server 汇报,上报状态、获取任务
- API Server 负责主要业务逻辑,以及集群间的调度、资源和任务的管理等等
- API Gateway 提供 API 给 UCloud 控制台(Console)
基于 HTTP 的通信
系统内的所有通信都基于 HTTP。
首先,Mesos 内部基于 libprocess 各组件之间的通信都都依赖 libprocess 库,该库用 C++ 实现了 Actor 模式。每个 Actor 会监听 HTTP 请求,向 Actor 发消息的过程就是把消息体序列化后放在 HTTP 报文中,然后请求这个 Actor。
其次,业务相关的各个组件,API Server、Cluster Server 等也都通过 Restful 的 API 提供服务。
HTTP 的优点在于简单可靠、易于开发调试和扩展。
VM Scheduler
对于 Docker 容器,我们采用 Marathon Framework 进行管理。而对于虚拟机,我们则采用自己开发的 VM Scheduler Framework 。
VM Scheduler 从 Master 获取一个个的资源 offer 。一个资源 offer 包含了某个 Agent 上可用的资源。当有虚拟机任务需要执行是,Cluster Server 会把任务的具体信息发送给 VM Scheduler。
任务分为两类:
- 创建/删除一个虚拟机。此时需要传入虚拟机的配置信息、包括镜像、网络、存储等。VM Scheduler 根据这些信息,匹配满足要求的 Resource Offer,然后生成 Task 提交给 Mesos Master 去执行。
- 操作一个虚拟机,如开关机、重启、镜像制作等。此时 VM Scheduler 会和 VM Executor 通过 Framework Message 通信,告诉后者去执行具体的操作。
VM Executor
Task 是 Mesos 中资源分配的最小单位。Master 会告诉 Agent 需要执行哪些 Task,Agent 也会把 Task 的状态汇报给 Master。根据 Task 的信息,Agent 会下载并启动所需的 Executor,然后把具体的 Task 描述传给它。
VM Executor 是我们开发的对虚拟机的生命周期进行管理的 Executor,实现了对虚拟机创建、删除、开关机、镜像制作等功能。
VM Executor 启动后,根据 Task 的描述,动态生成虚拟机需要的配置文件,然后调用 libvirt 进行虚拟机创建。当收到来自 VM Scheduler 的 Framework Message 时,又调用 libvirt 进行开关机等操作。
状态的管理是实现虚拟机管理的关键部分。通过 Mesos 我们只能拿到 Task 的状态,RUNING 表示虚拟机创建成功,FAILED 表示虚拟机失败,FINISHED 表示虚拟机成功销毁。然而除此之外,一个虚拟机还存在“开机中”、“关机中”、“关机”、“镜像制作中”等其他状态。我们通过在 VM Executor 和 VM Scheduler 之间进行心跳,把这些状态同步给 VM Scheduler。后者对状态进行判断,如果发现状态改变了,就发送一条状态更新的消息给 Cluster Server,然后再转发给 API Server,最终更新到数据库。
虚拟机的调度
首先看一下一个 Task 在 Mesos 中是怎么调度的:
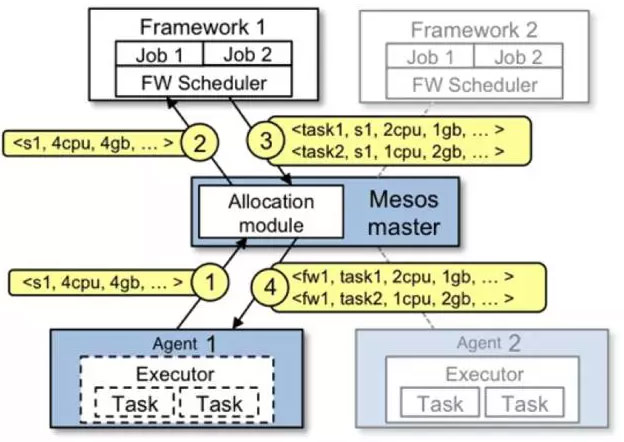
图4:Mesos 资源调度过程示意图
上面的示例中:
- Agent 向 Master 汇报自己所拥有的资源
- Master 根据 Dominant Resource Fairness(DRF) 调度算法,把这份资源作为一个 resource offer 提供给 Framework 1
- Framework 1 根据自己的业务逻辑,告诉 Master 它准备用这份资源启动两个 Task
- Master 通知 Agent 启动这两个 Task
对应到虚拟机的情况,调度分两个部分:
- 选择集群。默认情况下,API Server 根据资源需求,从注册上来的集群中选择一个拥足够资源的集群,然后把资源需求分配给该集群。另外,还可以针对不同的公司、项目等维度制定在某个集群运行;
- 集群内调度。Cluster Server 从 API Server 处获取到资源需求,比如说需要 200 个核,于是根据 Mesos 当前资源使用情况,创建出一个“资源计划”,200个核被分配为4个48核虚拟机和1个8核虚拟机。然后通知 Framework 按照这份计划来创建5个Task。
资源的标识
服务器之间除了 CPU、内存、硬盘等可能不同外,还会存在其他的差别。比如有时候业务要求一定要用某个型号的 CPU,有时候要求一定要拥有 SSD等等。为了支持更多维度的调度,我们利用了 Mesos 的 Resource 和 Attribute 来标识不同的资源。
Resource是 Mesos 中的一个概念,表示一切用户需要使用的东西。Agent 默认会自动添加 cpus, gpus, mem, ports 和 disk 这5种资源。另外还可以在 Agent 启动时,通过参数指定其他资源。
Attribute 以 Key-Value 形式的标签,标识一个 Agent 拥有的属性,同样可以在启动时通过参数指定。
通过 Resource 和 Attribute 的灵活运用,可以标识出更多的资源情况,满足各种资源调度需求。比如通过 Resource 指定 SSD 大小、CPU型号,通过 Attribute 标识机架位、是否拥有外网 IP,是否支持超线程等等。Framework 收到一个 resource offer 后,与待执行的任务需求进行匹配,通过 resource 判断资源是否够用,再通过 Attribute 判断是否满足其他维度的需求,最终决定是否用这个 offer 来创建 Task。
镜像、存储和网络管理
平台提供了一些基础镜像,另外用户也可以基于自己的虚拟机创建自己的镜像。这些镜像文件统一存储在一个基于 GlusterFS 的分部署存储服务中,该服务挂载在每台物理机上。
有些业务场景需要部分虚拟机能够共享同一份存储,于是我们还是基于 GlusterFS 开发了用户存储服务,能够根据用户的配置,在虚拟机创建时自动挂载好。
网络方面,每个用户可以创建多个子网,各个子网之间做了网络隔离。创建虚拟机时,需要指定使用哪个子网。
其他问题
在使用 Mesos 的过程中,我们也遇到了其他一些问题。
问题一:Marathon选主异常
当机器负载比较高,尤其是 IO 较高时,我们发现 Marathon 集群有概率出现不能选主的情况。
我们怀疑是由于Marathon节点和ZK的网络不稳定,触发了Marathon或Mesos的bug导致。于是通过iptables主动屏蔽Leader ZK端口的方式,成功复现出问题。
通过在Marathon的代码中加上一些Leader选举相关的最终日志,成功定位到了问题,原来是由于Mesos Driver的stop() 方法没有成功引起 start() 方法退出阻塞导致。
由于我们的所有程序都是通过守护进程启动的,所以我们采用了一个最简单的解决方案:修改Marathon代码,当ZK异常发生时,直接自杀。自杀后守护进程会把程序再启动起来。
问题二:go-marathon问题
我们的服务采用 Golang 开发,使用 go-marathon 库与 Marathon 进行交互。使用过程中发现该库有一些问题:
不支持多Marathon节点。于是我们自己创建了一个分支,采用节点主动探测的方式,实现了多节点的支持。(原库v5.0版本以后也支持了该功能)使用设有 Timeout 的 http.Client 进行 go-marathon 的初始化时,订阅 SSE 会产生超时问题。于是我们做了修改,普通的 HTTP API 和 SSE 不使用同一个 http.Client,操作 SSE 的 http.Client 不设置 Timeout。
网络异常时,go-marathon 的方法调用会 Hang 住。于是我们所有对 go-marathon 方法的调用都加上超时控制。
结语
Mesos 在UCloud有着广泛的应用,伴随着持续的实践,我们对 Mesos 的理解和掌控也越来越深入。我们会持续输出使用经验,欢迎探讨。

评论前必须登录!
注册