在一个项目中用Docker来构建NodeJS的服务器,Docker能够实现一致的编译,还有很好的可移植性,然而,在实现持续交付的过程中,一个问题出现了:build一个镜像要花12分钟的时间。
我们的Dockerfile文件是这样的:

必须要在build时添加–no-cache的flag,否则在第一次build后所有的更新都会被忽略。这样的话每次build要花15分钟安装node_modules,并且要添加1GB的缓存数据。这个过程必须要优化。
Docker是一层一层地生成容器镜像的。Dockerfile的每一行命令都创建新的一层,包含了这一行命令执行前后文件系统的变化。
为了优化这个过程,Docker使用了一种缓存机制:只要这一行命令不变,那么结果和上一次是一样的,直接使用上一次的结果即可。
为了充分利用层级缓存,我们必须要理解Dockerfile中的命令行是如何工作的,尤其是RUN,ADD和COPY这几个命令。
Run代表在容器中运行一个命令,语法如下:
RUN <command> <args>
RUN命令只有在其生成的层没被缓存时,才会执行。所以在build一个只包含RUN命令的Dockerfile时,只会真正build一次,下一次build,Docker会使用上一次的缓存。
当然,可以实现在下一次build时强制重新build:
- build时使用–no-cache标志,笔者看来这个办法最好不用,因为没有任何层缓存,build必然会慢很多;
- 弄明白ADD和COPY是如何让层缓存失效的,下面将讨论这种方式:
- 改变RUN命令行的形式,这里的问题和第1点一样,还需要一个build前的步骤,每次生产一个不同的Dockerfile;
ADD和COPY命令向正在构建的容器中引入了外部文件,语法如下:
COPY <external file(s)> <directory> ADD <external archives(s) or URL(s)> <directory>
ADD和COPY命令总是会被执行,外部文件从archive或URL中获取,写入到硬盘上。一旦获取到文件,Docker会将它和上一次build时获取的文件比较。
- 如果没变化,这个层缓存会被使用,直到下一个ADD或COPY命令之前,都使用上一次build的缓存。
- 如果有变化,这个层缓存将失效,之后所有的命令行都会被执行;
显然加速容器build的方式就是:跳过那些执行时间很长的RUN命令,直接使用上一次build的结果。
理想的过程是:
- 安装节点模块,如果它们有变化的话;
- 复制repo;
- 运行build过程,如果代码有变化的话。
这意味着要根据情况,在安装node-modules前以及克隆代码仓库前,让缓存失效。优化后的Dockerfile如下:
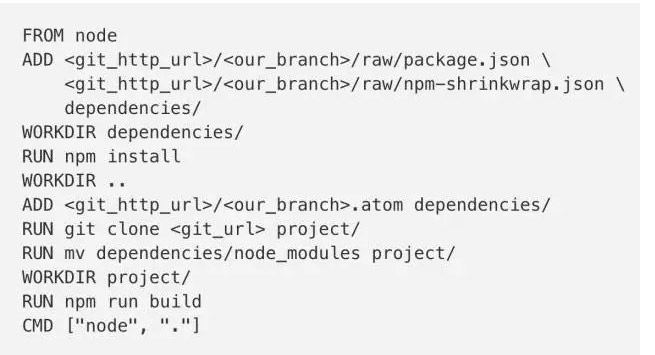
首先从Git中ADD package.json和npm-shrinkwrap.json,如果它们没变化,就可以直接用层缓存,节省了依赖安装的时间。
接下来要让缓存无效,否则相同的层缓存总会使用相同的代码。我们通过ADD Git服务中代码分支commit的ATOM feed,来另缓存失效。像GitHub或Gitlab这种服务都提供了类似的API,能定位到最新的代码commit。
如果代码没变,整个容器build的过程中,层缓存会被一直使用。如果代码发生了变化,Docker会运行clone命令行,移除依赖,执行build过程。
由于我们的依赖很少变更,所以通过这种方式,大多数build都能节省10分钟的时间。如果代码没变,build时间就几乎为0,因为只有3个HTTP请求,其它所有的都用了层缓存!

评论前必须登录!
注册