作者介绍
周晖,Pivotal大中国区云计算首席架构师,有丰富的PaaS云实际建设经验,负责过国内某知名银行已经生产上线一年的PaaS云的架构设计和部分功能的实现,参与过某超算PaaS、某超市电商PaaS、某电力PaaS等项目的建设。
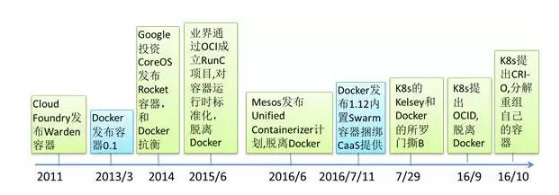
我们在上篇文章中谈到CaaS生态圈的公司如何应对Docker用捆绑方式从容器入侵CaaS领域,CaaS厂商通过容器抽象、标准化容器运行时RunC以及容器功能外化插件来重新定义容器。下面我们继续来看CaaS厂商的具体方案。
一、CaaS业界通过分解重组Docker技术来替代Docker的方案
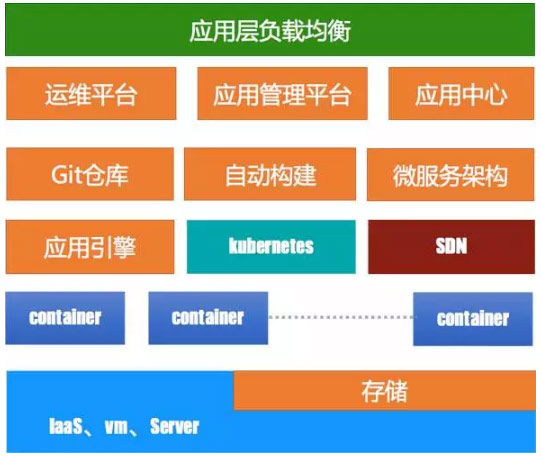
1、K8s通过CRI-O取代Docker容器管理引擎架构
和Cloud Foundry的架构模式类似,K8s也发展了CRI-O来取代Docker,架构图如下:
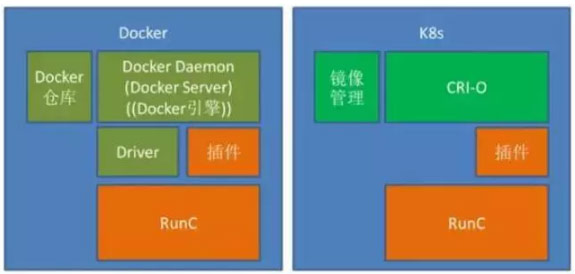
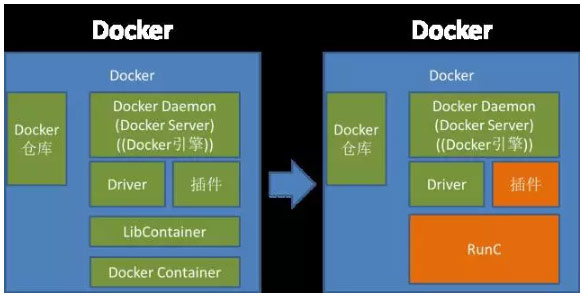
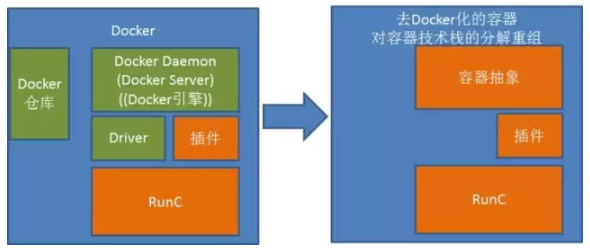
CRI-O是Google的Kelsey和Docker CTO所罗门论战之后的结果。论战之后,Google就提出一个设想,要让K8s调度的容器去Docker化,虽然他们一开始说的是要分支出一个Docker的分支来做容器,但是后来考虑到这样做属于刺刀见红,杀伤力太大,所以在2016年6月先弄了一个OCID(OCI守护进程),就是RunC的守护进程,和Docker Daemon有异曲同工之妙,该项目的维护人员此地无银三百两的说“这不是Docker的分支”。
由于OCID过于和Docker Daemon类似,随后Google又把这个项目重新命名为—CRI-O(Container Runtime Interface,容器运行时接口,O表示OCI,也就是RunC的运行时接口),这也反映了Google的心态,一方面通过CRI对容器进行抽象,什么容器我都支持,另外加一个O,我重点支持OCI的RunC,显得不是那么白刀子进红刀子出,大家表面上还是和平共处,而且显得立意更高,通过容器抽象层进一步标准化容器,RunC只是标准化容器运行时,CRI把对容器的调用管理等也标准化,潜台词是Docker Daemon是非标准的、独家的。
同时,Google也在向Mesos推销其CRI-O,希望Mesos也采用其CRI-O的架构。
CRI-O对容器运行时提供基本管理功能,同时Google的K8s提供镜像管理功能(Container/Images),完全可以取代Docker的镜像仓库。K8s一方面支持容器插件技术,另一方面自己也制定实现一些容器插件,最典型的就是容器网络插件,自己定义并实现了CNM的容器网络插件。
因为K8s之前一直支持Docker,为了保持一定的兼容性,K8s继续支持Docker容器,但是不再支持Docker超出标准容器之外的特定功能,也就是把Docker的定位和RunC等同化,Docker做的再多功能也不用。
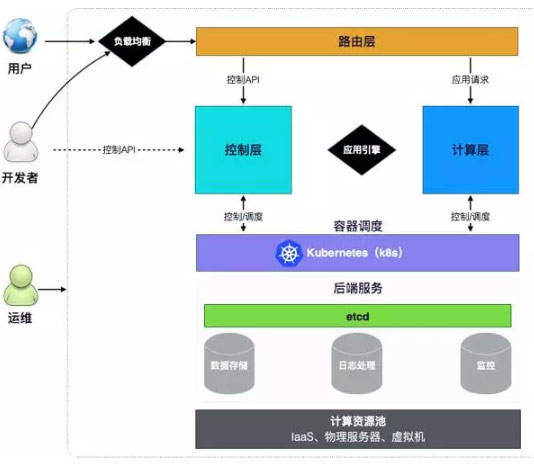
2、Mesos通过UnifiedContainer取代Docker容器管理引擎
和K8s类似,Mesos也不再只支持Docker容器,而且对容器进行了抽象,项目名字直接就叫”Unified Containerizer”—统一容器。目前还是支持 Docker 和 Mesos Containerizer 两种容器机制,未来就统一到”Unified Containerizer”。架构图如下:
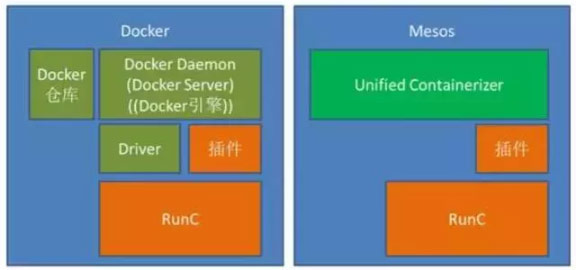
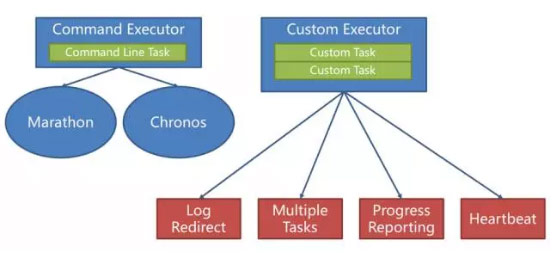
Unified Containerizer也支持插件架构,但是和Docker的插件不是完全一样,设计的插件类型更丰富,包括三大类:
- 第一类是进程管理,支持容器之前的进程,这也是Mesos一贯的调度管理策略。
- 第二类是隔离器: 在容器生命周期的各个阶段提供扩展接口,保护了Docker的几类插件,如网络、磁盘、文件系统、卷插件。
- 第三类是容器镜像管理,除了容器镜像,还将支持虚机镜像等。
Mesos的统一容器基本就包含了DockerDaemon、Docker仓库等功能。
当然,由于之前一直支持Docker容器,目前阶段Mesos还继续支持Docker,但是也有自己的Mesos Containerizer容器机制。
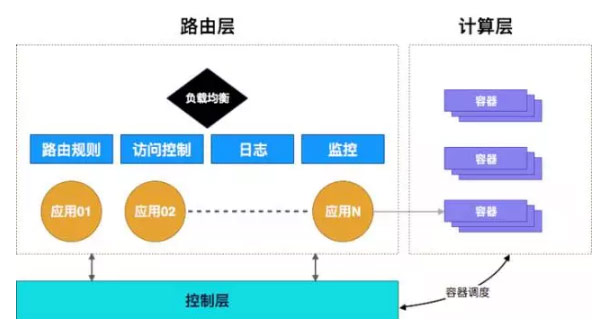
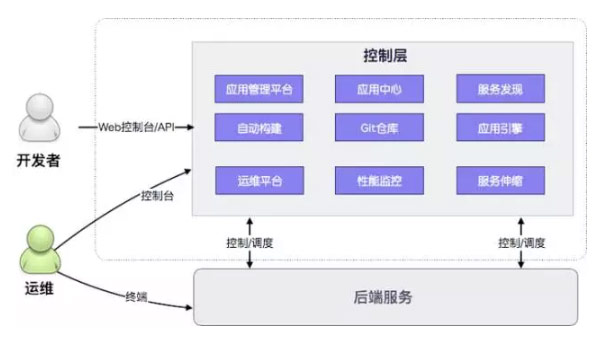
3、Cloud Foundry通过Garden取代Docker容器管理引擎
从RunC逐步成熟,Cloud Foundry的容器引擎Garden就采用了RunC作为容器运行时,如下图:
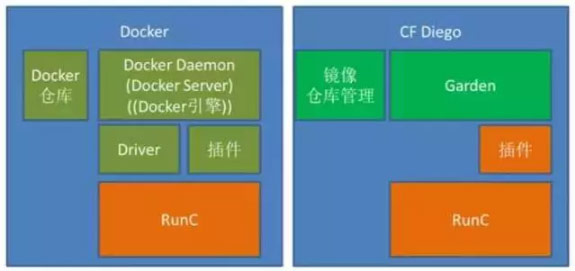
Garden取代DockerDaemon(Docker Daemon有内有Docker Server,Docker Server内有Docker引擎),直接调用RunC来生成容器运行环境,同时CFGarden也支持容器插件,容器插件是独立进程,在网络插件方面优先支持K8s的CMN插件标准。CF Diego有自己的镜像仓库管理,也可以从Docker仓库中获取Docker镜像部署。
这里,我们不得不对Garden的设计多说几句,Garden包括之前的Warden,从一开始的设计就是容器抽象,使得可以支持不同的容器运行时,而且Garden做了三层抽象,所以Garden从一开始就支持.Net应用,不是通过Windows 2016的容器机制来实现,而是在.Net运行时模拟了一个容器的实现,所以Garden支持Windows的几乎所有版本的.Net应用。
K8s CRI-O和Mesos的UnifiedContainerizer都借鉴了Garden的容器抽象设计思路,所以Garden也是第一个支持RunC的CaaS/PaaS。
从这个架构可以看出,Cloud Foundry的Garden基于RunC和容器插件,就替代了Docker的容器功能,共同的是RunC和容器插件,而Garden取代Docker Daemon的容器管理功能。
当然,Garden也支持直接部署Docker镜像。
二、容器生态的演进
1、各方以RunC为核心重新构建容器生态圈,Docker容器被弱化
在对开源Docker分支进行了反复斟酌、放风声、试探和讨论之后,各方觉得杀伤力太大的方案。而重新回到了折中方案,以RunC为核心重新构建生态圈,并且通过插件来弱化容器在CaaS生态圈的重要性。
我们来看看生态圈的演进示意:
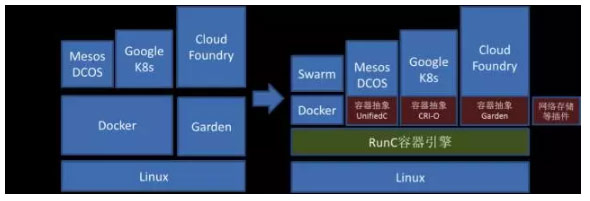
此图标识了容器生态圈或是CaaS的演进变化
最早只有Docker和Garden两大主流容器,Mesos和Google都专注于CaaS,容器就全部采用Docker,CloudFoundry由于在Docker之前就推出了Warden(后升级到Garden)容器,CF采用自己的容器打造了PaaS平台,形成了一个和谐的生态。
在Docker捞过界了,并且确实有些不符合企业生产系统的因素,包括后向兼容性、商标问题、稳定性问题,于是各CaaS/PaaS生态厂商组建OCI联盟,打造RunC容器引擎,只需要一个简单的容器起停、管理等引擎,把Docker的容器功能一分为二,RunC作为一个简单明了的运行环境,降低复杂度,提升稳定性,适合生产系统。而对于Docker容器的其他功能,则在各自的容器抽象层,依据需要去实现,而且因为Docker本身集成了太多功能,不利于生产环境稳定性要求,各个容器抽象层都采用插件模式,维持容器的简洁性,需要什么功能再插入容器,比如需要网络就可以插入网络插件,需要存储和卷访问,就插入存储和卷的插件。
目前的形势,就形成了Docker和各个CaaS/PaaS厂商在同一层面竞争,在CaaS/PaaS平台,Docker并没有什么优势,但是Docker想把其容器的广泛使用的优势在CaaS中延续,目前看来并不容易。容器的主要用户还是个人用户、开发者用户、运维用户,而CaaS是企业系统,二者目标客户不同、技术要求不同。
随着这个生态的演进,Docker容器会更多的用于开发、测试环境,而RunC在各个CaaS厂商的推动下会在生产环境得到广泛的应用。
K8s目前基本只支持RunC容器,对于Docker超出其容器抽象层之外的功能,一概不支持。同样,Mesos也通过其Unified Containerizer只支持RunC容器,目前还支持Docker,但是未来的规划是只支持Unified Containerizer。CF也通过Garden只支持RunC,不支持Docker超出RunC之外的功能。
2、RunC生态的快速发展
由于Docker的消极抵制,RunC的发展好像并不为人所知,但是RunC的发展还是很快的,RunC本身就简单,通过版本的持续的迭代更新,目前已经达到生产可用,而且主流的PaaS/CaaS纷纷采用。Docker也从1.11开始内置RunC容器运行时。
除了RunC本身的发展,RunC的生态圈也在快速发展,这个生态圈就脱离了的Docker。比如最近的Riddler,就是一个把Docker容器转换为RunC镜像。
详见https://github.com/jfrazelle/riddler。
三、你还只用Docker吗?
Docker作为目前最热的容器开源项目,受到广泛的追捧。但是也要清醒地看到Docker和容器生态圈的种种争斗,Docker通过注册商标和在Docker中内嵌容器集群管理,挤压生态圈其他公司的生存空间,而受到生态圈联盟以RunC和相应的技术来制约Docker。
如果你是开发测试用Docker,那么基本不受影响,可以继续,这也是很多公司对Docker的定位。如果你是生产系统采用Docker(包括Swarm),你就要注意,如果是你自己定制开发基于Docker/Swarm的CaaS(Container As a Service),那问题也不大,出现漏洞或是定制可以自己打补丁,但是要意识到你的补丁不一定能合并到Docker的主干版本。如果是你采用的是第三方给你定制的基于Docker和Swarm的CaaS,你就一定要当心了,他们针对Docker做的定制要合并到Docker的后续版本有相当的难度,因为对于Docker的补丁定制合并,除了Docker公司其他公司几乎是没有什么控制力度的,还包括后向兼容性问题。
作为用户或是容器生态圈的创业公司,不能一棵树上吊死,如果在容器层面只考虑Docker,而不考虑RunC,可能会和CaaS/PaaS生态圈的标准越来越远,未来和CaaS/PaaS的标准容器差异越来越大,主流的CaaS/PaaS厂商和技术,如K8s/Mesos/CloudFoundry均不再支持Docker容器超越RunC之外的功能,而只支持插件对RunC功能的扩展。
业界更普遍的定位是Docker用于开发测试环境,而RunC用于生产环境,所以对于要在生产环境采用容器技术的,一定要研究RunC。
作为容器创业公司,很多是在Docker的风口成立的,但是由于Docker一家独大和Docker注册商标的法务问题,可能还没有在风口起飞。应当可以考虑在OCI/RunC的生态圈进行相关技术的发展,OCI/RunC的生态圈受到实力强大的几家公司的强力支持,如Google、CF基金会、Pivotal、Redhat、Mesos、CoreOS等。而且RunC的生态圈还刚刚起步,还有很大的发展空间。而且作为技术创新,对于技术的前瞻性判断非常重要,方向判断正确,一路辛苦是披荆斩棘,方向判断错误,一路辛苦也是前程堪忧。
国内的公司对RunC的贡献度越来越高,特别是华为,可能是国内公司中对RunC贡献最大的。还有EasyStack、南大索芙特等的贡献,反倒是一些著名的Docker创业公司看不到对RunC的贡献。这一方面反应了华为、EasyStack技术眼光和对社区的贡献,另外也反映了为什么华为和EasyStack在商业上也更成功一些。
四、对一些问题的提前答复
1、RunC也是Docker的,用Docker和用RunC不是一样的吗?
Docker对RunC有重大的贡献,RunC的早期也是基于DockerLibcontainer,但是RunC在OCI下独立发展,有贡献的厂商远远不止Docker。在RunC项目后,在OCI的推动下,各个厂商积极贡献,Docker的代码贡献并不占主导,更谈不上主要是Docker在维护,更准确的说Docker是RunC的重要维护力量之一。
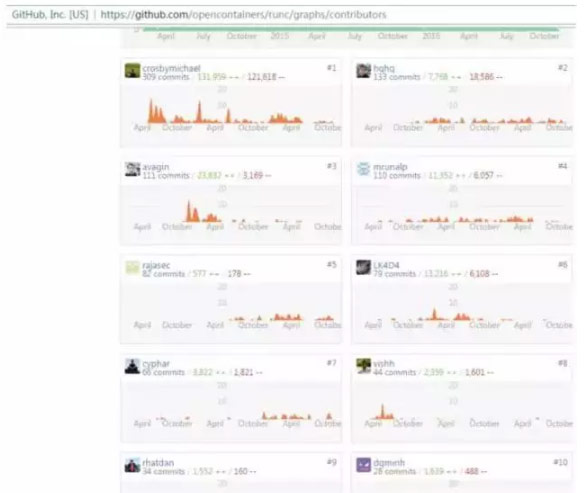
上图是Git上RunC的代码贡献者排名
前10个贡献者中,Docker只占2位,不得不提国内的公司华为代码贡献排名是相当的靠前。而且RunC的代码贡献者超过100人。
除了Kubernetes/Mesos/CloudFoundry支持RunC容器运行时,Docker的容器从1.11开始也内置RunC作为容器运行时,说明RunC受到最为广泛的支持。
而K8s/Mesos/CloudFoundry明确表示在容器抽象层不再支持Docker超越RunC之外的功能。
RunC属于OCI,不再受Docker注册商标的影响,对RunC的代码贡献不再受限于Docker。
用RunC相当于给你一个干净简单的容器运行时,用Docker相当于不管你要不要,强塞给你一堆可能你不想用的东西。
对于RunC和Docker的详细技术区别,请参考《容器,你还只用Docker吗?(上)》中的4.5章的内容。
2、在Docker如日中天的时候这么说是哗众取宠
Docker现在是如日中天,但是3年前也是刚起步,也许可以说RunC就是3年前的Docker。Docker由于Docker公司自身的商业特征,对容器生态圈其他公司的生存空间的挤压,已经造成了容器生态圈的裂变。
“风起于青萍之末”,如日中天的时候可能就是走向下坡路的开始。Docker一家和其他CaaS生态圈分裂,这条路注定是不平坦的。
3. 黑Docker黑出翔来了
黑Docker的资料很多,所有资料都有出处,有参考内容链接,详见后面的引用。
Docker已经被布道师们说成”无所不能”,稍微有几个不能,我觉得大家还是能区别得出来。
4. RunC是没人管的孩子
RunC的自身发展远不如Docker那么有名气,因为RunC本身就是一个很小的容器运行时,不是针对开发者的,开发者往往是通过Docker接触到RunC,所以RunC的受众远比Docker要少。
但是对于CaaS项目来说,K8s/Mesos/CloudFoundry往往就是基于RunC容器运行时。
RunC的社区也很活跃,除了RunC本身的更新很快,各大CaaS/PaaS生态圈如Google/Pivotal/Redhat/华为/CoreOS等都有专人在贡献代码。
RunC相应的生态空间也在活跃,也有不同的项目在进行中。
RunC是CaaS/PaaS/OCI等生态圈共同的孩子,不是没人看的孩子。
5、容器不需要标准更好
业界也有一些人持这个观点。其实,标准的价值是常识,当然总会有反常识的言论出来。没有标准就没有合力,没有合力哪来的发展。如果Docker公司把闭源,那可以没有标准。既然是开源,又想要生态圈的其他公司和力量做贡献,就要让大家有合力,就要让大家在标准的基础做贡献,而不是把生态圈的其他公司当作免费打工的。
五、总结和展望
Docker和CaaS生态圈在容器上的分裂已经是现在进行时了,虽然大家都没有明说。这也将是容器和CaaS生态圈重要转折事件。让我们来看看目前正在发生的和在未来一年中很有可能发生的事情:
Cloud Foundry率先采用RunC作为容器运行时,而且刚刚做了一个25万个容器集群的测试,https://www.cloudfoundry.org/cloud-foundry-approaching-250000-containers/ 验证了PaaS+RunC的大规模集群的支持。
K8s的CRI-O也会尽快发布,等CRI-O成熟以后,内置的容器运行时就应当是RunC,而不再是Docker了。
Mesos的Unified Containerizer 也应当会在1年之内成熟,随后内置的容器应当也是RunC,而不再是Docker。
在Docker被科普以后,客户更关注的是CaaS而不是容器,再给客户去科普Docker体现不出容器创业公司的价值。
一些不适合容器的Docker应用场景的案例会被证伪,在Docker和容器鲜为人知的时候,各种各样的Docker案例层出不穷,包括一些明显和常识有违的案例,比如交易系统采用Docker, 交易极严格的延时的要求不适合Docker。有的是故意混淆概念,交易本身不在Docker容器中,交易系统相关的一些模块在Docker中,为了突出宣传效果,说交易系统采用Docker。
Docker创业公司分化,越来越多的容器创业公司给别人介绍自己的时候会说我们是K8s初创公司(或我们是Mesos创业公司),不是Docker创业公司,强调自己是CaaS厂商,突出自己不是Docker厂商。当然,也有纯Docker的创业公司,但优势会变成劣势,毕竟在CaaS领域,Docker没有优势。
Docker在容器失去了K8s/Mesos/CloudFoundry的支持之后,会更专注于Swarm,和CaaS的其他厂商的竞争将更直接,但是Docker公司一贯的对企业生产环境特性的不在乎,Swarm很难对其他CaaS形成竞争优势。
RunC的生态圈将越来越丰富,第一个就是把Docker镜像转换为RunC标准镜像(这个已经有了),其次就是各种各样的插件和RunC可以交互,中间还可以衍生出各种插件的功能,如即插即用(动态性)、自动发现之内的。
一年以后,我们再来复盘。