编者按:随着越来越多的企业逐渐将Docker和容器技术应用于自身的IT架构并广泛投入生产实践,容器监控变得愈发重要。而相比于传统主机,容器需要监控的指标将成倍增加,如何监控并管理好系统中大批量的容器已成为运维人员必修的重要课题。希望本文能够为正在使用Docker容器的读者们提供一个关于容器监控方面更为清晰的数据画像。

容器监控没你想得那么简单
容器在很多人的概念里可以看作是迷你主机,而主机运维历经多年的实践已经形成了非常健全的方法和机制,因此你可能会觉得容器的运维也可以复制相同的套路,然而实际情况却并非如此。
传统主机到容器的演变
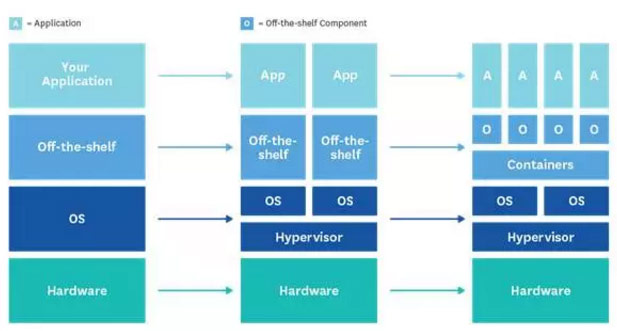
从上图可以看到过去15年来标准应用架构的变迁:
左:大约15年前的应用架构
中:大约7年以前,随着虚拟化技术的广泛采用,整体架构的演进带来了更高的资源利用率和更快捷的主机配置,但这些对于一个工程师来说几乎没有太大的变化
右:如今,在虚拟化的硬件上运行容器化的stack变得越来越普及,运维人员也将面临更多更复杂的监控指标
容器监控指标的成倍增长
在应用容器之前,你可能只需要对每个EC2主机监控150个指标:

而如今实现了容器化以后,针对每一个容器,除了需要采集至少50个容器本身的指标以外,还需要采集至少50个容器上运行的组件的指标,这样看来,我们就需要为每一个容器添加至少100全新的监控指标。根据数据统计,一般每个主机运行着至少4个容器,可以大致算出每个主机需要监控的指标数量:
OS +(Containers per host * (Container + Off-the-shelf)) =
100 + (4 * (50+ 50)) = 500 metrics per host
假设你的系统有100个实例,那就是50000个监控指标!

如何简化容器监控
通常来讲,一般在生产环境中会使用大批量的容器并且每个容器有着较短的生命周期,这就导致运维的复杂性会大幅增加。正因如此,为简化监控难度,不少容器化的应用栈并不会去监控容器本身,这样一来就造成了一个巨大的系统监控盲点并为系统带来了可能宕机的风险和缺陷。那么如何全面监控容器并尽可能地简化整个过程呢?以下两点可能会帮到你。
1. 统一监控应用架构中的所有层级,这样可以在同一时间直观的了解各个层级的系统状态,避免各层级之间的gap影响运维判断。
2. 标注系统中的这些容器,这样就可以按照可检测的集合来统一管理它们,而非一个个单独监控。
主要的Docker资源指标
那么在实际运维过程中,面对茫茫多的监控指标,到底应该重点选择哪些主要的Docker资源指标去监控呢?
CPU指标
| 名称 | 描述 | 指标类型 |
| 用户CPU | CPU受进程直接控制的时间百分比 | 资源使用情况 |
| 系统CPU | CPU执行系统调用进程的时间百分比 | 资源使用情况 |
| 节流(数) | 容器的CPU限制执行数 | 资源饱和程度 |
| 节流(时) | 容器的CPU使用率被限制的总时间 | 资源饱和程度 |
标准指标
就像传统的主机一样,Docker容器可以报告系统CPU和用户CPU使用情况。如果你的容器执行缓慢,毫无疑问CPU会是你想要重点查看的资源之一。
节流
如果Docker有足够的CPU容量,但仍然怀疑计算资源被占用了,这时你一定想要检查一项容器特定的指标:CPU节流。
如果不指定任何调度优先级,则可用CPU时间将在运行容器之间均匀分配。如果某些容器不需要所分配的CPU时间,那么它将按比例地提供给其他容器。这样我们就可以通过设定共享CPU来选择性地控制每个容器使用的CPU时间份额。
更进一步来说,我们可以主动限制容器。在某些情况下,容器的默认CPU共享份额会实际比我们希望的要高。如果在这些情况下,CPU配额限制将告诉Docker何时限制容器的CPU使用率。值得注意的是,CPU配额和CPU周期都以微秒(而不是毫秒或纳秒)表示。因此,如果在0.1s周期内尝试使用超过一半的CPU时间,则具有100,000微秒周期和50,000微秒配额的容器将被节流。
Docker可以告诉我们每个容器执行限制的次数,以及每个容器被限制的总时间。这些指标可以从伪文件,stats命令(基本CPU使用情况度量标准)或从API收集CPU度量标准。
内存
Docker可以报告可用的内存量,以及它使用的内存量。
| 名称 | 描述 | 指标类型 |
| 内存 | 容器内存用量 | 资源使用情况 |
| RSS | 过程中的非缓存内存 | 资源使用情况 |
| 缓存 | 来自内存中缓存的磁盘数据 | 资源使用情况 |
| 交换 | 交换空间使用量 | 资源使用情况 |
使用过的内存可被分解为:
– RSS(resident set size)是属于进程的数据:stacks, heaps 等等。RSS本身可以进一步分解为活动和非活动内存(active_anon和inactive_anon)。非活动RSS内存在必要时会交换到磁盘中。
– Cache memory 反映当前缓存在存储器中的磁盘上存储的数据。缓存可以进一步分解为活动和非活动内存(active_file,inactive_file)。当系统需要内存时,非活动内存可以首先被回收。
Docker会同时汇报当前使用的交换量。
在调查性能或其稳定性中,有价值的附加指标包括page faults, 它表示分段错误或从磁盘而不是从存储器获取数据(分别为pgfault和pgmajfault)。
与传统主机一样,当出现性能问题时,我们需要查看的第一个指标应该是内存可用性(memory availability)和交换使用量(swap usage)。内存指标可以从伪问卷,stats指令(基本内存使用指标),或API中收集。
IO
对于每个设备,Docker可以报告以下两个指标,分解为四个计数器:读取与写入,以及同步与异步I / O。
| 名称 | 描述 | 指标类型 |
| I/O Serviced | 执行过的I/O数量 | 资源使用情况 |
| I/O Service bytes | 由cgroup读取或写入的字节 | 资源使用情况 |
Block I / O是共享的,因此,除了上文提到的容器特定的I / O指标之外,跟踪主机的队列和服务时间也是个好方式。如果容器使用的块设备上的队列长度或服务时间增加,则容器的I / O将受到影响。
网络
与普通主机一样,Docker可以报告几个不同的网络指标,每个网络指标分为显示入站和出站网络流量指标:
| 名称 | 描述 | 指标类型 |
| Bytes | 网络流量 | 资源使用情况 |
| Packets | 网络计数 | 资源使用情况 |
| Errors(收集) | 收到错误的数据包 | 资源错误 |
| Errors(传播) | 收到错误的数据传输 | 资源错误 |
| Dropped | 数据包丢弃(发送/接收) | 资源错误 |
容器监控指标和传统主机的差异
Docker可以报告传统主机所需的所有基本资源指标:CPU,内存,I / O和网络。但通常,我们需要收集的Docker资源指标与传统主机却不尽相同,某些特定指标(例如nice,idle,iowait或irq CPU时间)在容器监控中并不可用,而有些其他指标在传统主机中并不会使用,但对于容器来说却是唯一的,例如CPU节流等。
