大家好,我是起步科技的史绍虎,负责公司WeX5开发云平台的架构设计,今天跟大家分享的题目是《基于Docker的开发云提高资源利用率的实践》
一般情况下,开发者从无到有开发一个可用于公网访问的HTML5的App应用的流程是这样的:配置开发环境、开发应用、本地调试、租用公网服务器、注册域名、远程部署、远程调试,就算是一个很有经验的开发者,这整个过程还是需要花费不少时间,尤其是面对一个不断更新修改的应用。
WeX5作为HTML5 App的开发工具,很有必要为WeX5开发者提供一个从开发到部署、运维的一体化云平台,实现WeX5之上的DevOps,让开发者更专注于应用开发,而不再关注应用的部署运维。而WeX5也因此由比较纯粹的应用开发工具演变为“开发云”。
对于WeX5开发云来说,在实现DevOps时,其需求场景有两大特点:首先,开发者众多,用于测试演示的应用多,但是访问很少,并发低,资源利用率很低,同时又要求很高的响应速度,另一方面,WeX5开发云还提供在线设计IDE,这类IDE容器非常耗费资源,但是并发占用率不高,用户连续长时间使用的可能性也不大。
这就要求我们的WeX5开发云在有限的成本支撑下能够尽可能地提高资源利用率,并且保障应用的可用性,经过一番努力,我们探索出以下几条途径:
- 智能路由
- 自动启停
- 资源调控
- 动态应用部署
- 容器资源池
首先我们来看下WeX5开发云的基础架构层次,主要是让大家对整体架构有个映像,跟今天主题其实关系不大。
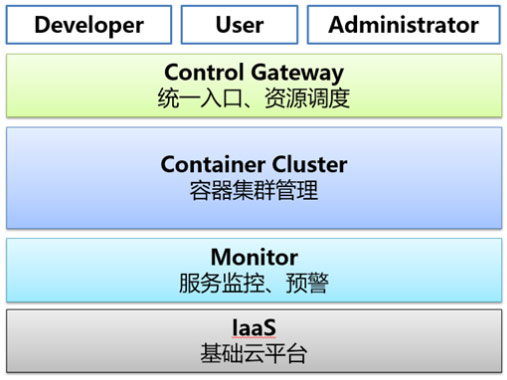
其中,Iaas层由阿里云支持,Monitor层采用Open-Falcon、Prometheus实现,Container Cluster采用Rancher+Docker实现,Controller Gateway由AutoStart、Regulator、IDE Pool、Proxy等组件组成。
下面来详细介绍下我们是如何提高资源利用率的:
一、智能路由
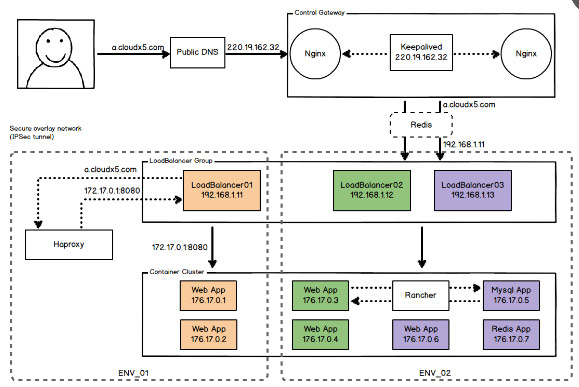
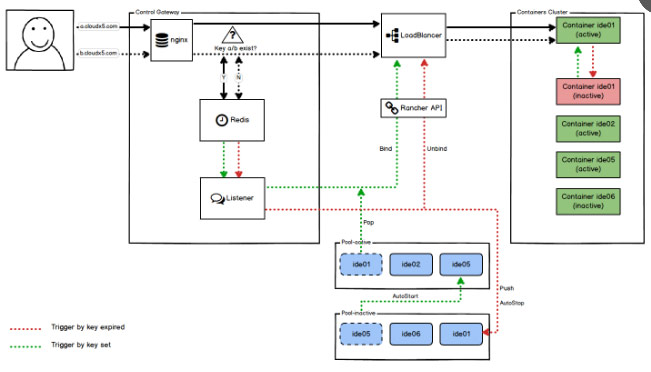
实现逻辑:创建应用的时候,会根据LoadBalancer集群的负载情况,选择一个负载较少的LoadBalancer作为该应用的路由网关,提供负载均衡及路由转发功能。控制网关接收到访问请求后,根据请求域名与LoadBalancer的映射关系,将请求转发到该LoadBalancer上。如上图所示,ENV_01与ENV_02的docker网络是隔离的,在同一个环境中,请求域名与LoadBalancer的绑定可以动态调配。
二、自动启停
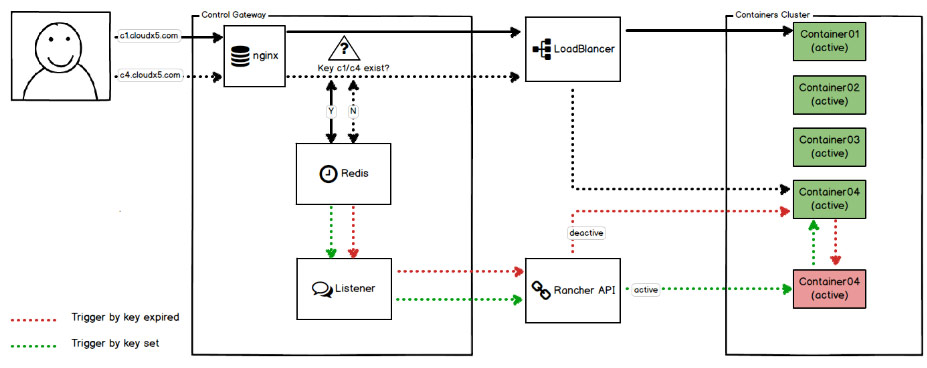
应对场景:目前WeX5开发云上的应用以开发者测试演示应用为主,这类应用的特点是数量多、访问少,甚至有很多应用创建后访问一两次,就再也没有访问,长此以往,这类应用会逐步占用大量的物理资源,如果按传统方法,直接将这些应用清除,又难以保证不会影响开发者的下一次使用,这就要求我们寻找一个既能为开发者不可预期的访问提供支持,又能保证资源的的最大化利用的解决方案。
实现逻辑:应用创建后系统默认应用是停止状态,控制网关接收到第一次访问的时候,会调用Rancher API启动该应用,并且在redis中为该应用记录一个生存时间,在该时间范围内,认为该应用是健康运行的,再次接收到的请求立即转发并刷新生存时间。若一段时间没接收到访问请求,生存时间结束,触发事件调用Rancher API接口停止该应用,释放物理资源。
三、资源调控
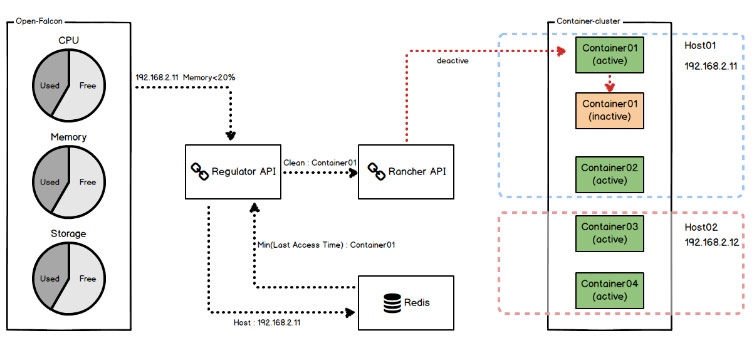
应对场景:为了最大化地利用物理机的资源,WeX5开发云引入了自动启停技术,物理资源会处于超售状态,超售能够降低成本,最大化地利用物理机的资源,但同时也会带来资源争取的情况,甚至会因为节点上运行状态容器的资源消耗量超出系统负荷,导致节点宕机。
实现逻辑:Redis中记录应用最后一次访问的时间,Open-Falcon中监控各个Host主机的物理资源,当某项物理资源指标达到预设阀值的时候,触发事件调用Regulator API,计算该主机上最后一次访问时间最早的若干个应用,并调用Rancher API接口将其停止,释放资源。
四、动态应用部署
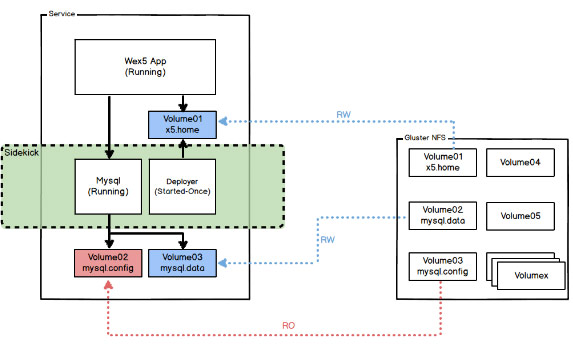
应对场景:开发测试过程中的应用往往需要频繁更新调整,对于有依赖关系的应用来说,频繁的中断服务会影响这些应用的可用性,即使是通过灰度滚动升级,也需要不断地调整链接参数。
实现逻辑:采用Rancher中的Sidekick机制,将整个的Wex5应用分为Wex5 app容器(负责运行时环境)、Mysql容器(负责数据存储)与Deployer容器(负责提供用户数据),当应用代码文件等有更新时,提交到Deployer并执行重启,即可完成整个Wex5应用的更新升级并且保证服务的不间断运行。
五、容器资源池
应对场景:WeX5开发云上提供了Wex5应用在线设计IDE,这个在线设计的应用也是跑在容器中的,但是由于设计器本身需要加载大量的资源文件,如果由开发者自行创建一个在线IDE的容器,从创建到正常运行大概需要30秒,时间等待较长,即使加入自动启停功能,第一次访问启动容器的时间也在15-20秒左右,用户体验太差,所以我们需要一个类似于数据库资源池的功能,将IDE容器与开发者资源分离,其中的IDE容器长时间处于运行状态,开发者获取该资源的使用权限后,只需要加载开发者的资源文件即可正常访问,这样就可以大大优化用户体验。
实现逻辑:IDE资源池为了节省物理资源,同样加入了自动启停机制,将资源池分为POOL_ACTIVE与POOL_INACTIVE两块,开发者访问在线设计功能时,控制网关首先接收到请求,从POOL_ACTIVE资源池中获取一个运行状态的IDE容器,与开发者的访问域名绑定,并且在redis中为记录一个生存时间,在该时间范围内,该开发者具有此容器的使用权限,再次接收到的请求立即转发并刷新生存时间,同时,从POOL_INACTIVE中启动一个备用资源补充到POOL_ACTIVE资源池中。若开发者一段时间没有访问该IDE资源,生存时间结束,该资源释放到POOL_INACTIVE,并删除开发者上传的资源文件。
总的来说,智能路由组件可以融合多个小网络形成一个大网络,自动启停组件及时释放无访问的应用所占用的资源,资源调控组件缓解了偶尔出现的峰值访问压力,动态应用部署组件让更新升级不再影响应用的可用性,资源池组件提供更快更稳定的访问体验,通过这些手段,可以做到在保障用户体验良好的前提下,大大提高了物理资源的利用率,有效地降低了运营成本。
对于开发者来说,开发流程简化为:本地开发(或在线开发)、一键部署、公网访问,不再繁琐、便捷高效、随时可用,这就是WeX5开发云实现此DevOps的意义之所在。
Docker使用过程中遇到的问题:
docker的存储驱动,早期我们使用的是docker默认的devicemapper(loop)的存储驱动,存在很大问题,尤其是数据盘的大小不是绝对固定的情况下,很容器导致docker数据丢失,建议采用devicemapper(direct-lvm)、overlayFS、AUFS等作为docker的存储驱动。
docker daemon服务执行重启操作的过程中,会执行docker 容器的启动操作,假如有容器强依赖其他容器的话,这个启动过程就会出现问题,例如我们使用Convoy NFS服务作为外部卷存储的统一提供者,其他docker容器需要挂载的volume由Convoy NFS统一管理,这时候如果Convoy NFS容器没有启动的话,挂载了volume的容器也无法启动,docker daemon的重启进程会不断尝试启动各个容器,直到把Convoy NFS容器启动起来,其他的容器才会慢慢正常启动,这个情况在容器量不大的情况下并不明显,但是如果主机上有几百个容器,这就会耗费很长时间,一度让我们怀疑系统是由于其他原因导致了宕机。Docker1.12中 Docker Daemon 添加了一个 –live-restore 的参数,使得当 Docker Daemon 停止运行时,容器仍然可以保持运行以解决此类问题。

评论前必须登录!
注册