前言
容器,近年来最火的话题,在后端的开发中,容器的运用已经是主流技术了。今天,我们就来说说容器技术。首先,虽然目前Docker技术如此火爆,但其实容器技术本质上并不是什么高大上的东西,总的来讲,就是对目前的Linux底层的几个API的封装,然后围绕着这几个API开发出了一套周边的环境。
目前来说,普遍讨论关于容器的文章,一开始都会讲到UTC隔离、PID隔离、IPC隔离、文件系统隔离、CGroups系统,今天这一篇,我们换一个视角,从以下几个方面来聊一下容器技术。
- 第一部分,从容器和虚拟机说起,都说容器是非常轻量级的,那么和虚拟机比起来,到底轻在哪里?
- 第二部分,通过构造一个监狱,来说明如何建立一个简单的容器,会涉及到容器的各种技术,当然还有一些没有涉及到的,我认为不影响理解。
- 第三部分,通过代码实战一把,看看如何一步一步按照第二部分的说明启动一个容器并运行自己的代码,这一部分的全部代码都在github上。
- 最后,我会再说一下Docker技术,因为Docker从代码来看,容器技术只是他的一小部分,完整的Docker远比单纯的容器要复杂,我会简单的说一下我对Docker的理解,包括Docker使用的其他技术点。
容器和虚拟机
要说容器,跑不了和虚拟机进行比较,虚拟机是比较古老的技术了,虚拟机的架构图如下所示。
虚拟机核心是什么?是模拟硬件,让虚拟机的操作系统以为自己跑在一个真实的物理机器上,用软件模拟出来CPU、内存、硬盘、网卡,让虚拟机里面的操作系统觉得自己是在操作真实的硬件,所以虚拟机里面的CPU啊,内存啊都是假的,都是软件模拟出来的(现在有硬件虚拟化技术了,比纯软件模拟要高级一些,但操作系统不管这些),既然操作系统都骗过去了,当然跑在操作系统上的进程同样也骗过去了呗,所以这些进程都完全感知不到底层硬件的区别,还以为自己很欢乐的跑在一台真实的物理机上了。
那么容器又是什么鬼?容器的架构图如下(图片来源于网络):
和虚拟机一个很明显的区别就是容器其实并没有模拟硬件,还是那个硬件,还是那个操作系统,只不过是在操作系统上做了一点文章【这张图中就是Docker Engine了】,让进程以为自己运行在了一个全新的操作系统上,有一个很形象的词来描述他就是软禁!就是把进程软禁在一个环境中,让进程觉得自己很happy,其实一切尽在操作系统的掌控之中,其实虚拟机也是,虚拟机是把操作系统软禁起来了,让操作系统觉得很happy,容器是把进程软禁起来,你看,一个是软禁操作系统,一个是软禁进程,这两个明显不是一个级别的东西,谁轻谁重不用说了吧。
既然容器和虚拟机的区别在于一个是通过模拟硬件来软禁操作系统,一个是通过做做操作系统的手脚来软禁进程,那么他们能达到的效果也是不一样的。
- 对于虚拟机来说,既然是模拟的硬件,那么就可以在windows上装linux虚拟机了,因为反正是模拟硬件嘛,虚拟机内部的操作系统也不知道外面的宿主机是什么系统。
- 容器就不一样了,因为是在操作系统上做文章,所以不可能在linux上装windows了,并且还有一点就是,容器内的操作系统其实就是外面宿主机的操作系统,两者其实是一个,你在容器内用uname -a看到的内核版本和外面看到的是一样的。本质上容器就是一个进程,他和宿主机上任何其他进程没什么本质的区别。
建造容器监狱
如何来做一个容器呢?或者说容器是怎么实现的呢?我们从几个方面来说一下容器的实现,一是最小系统,二是网络系统,三是进程隔离技术,四是资源分配。最小系统告诉你软禁进程所需要的那个舒适的监狱环境,网络系统告诉你软禁的进程如何和外界交互,进程隔离技术告诉你如果把进程关到这个舒适的监狱中去,资源分配告诉你监狱里的进程如何给他分配资源让他不能胡来。
建设基本监狱【最小系统打造】
要软禁一个进程,当然需要有个监狱了,在说监狱之前,我们先看看操作系统的结构,一个完整的操作系统【Linux/Unix操作系统】分成三部分,如下图所示【本图也是网上找的,侵权马上删,这个图是四个部分,包括一个boot参数部分,这不是重点】。
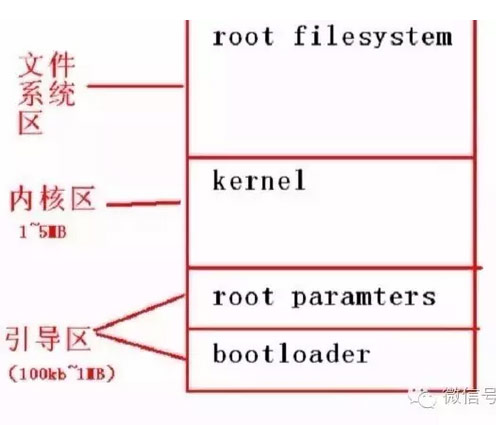
首先是bootloader,这部分启动部分是汇编代码,CPU从一个固定位置读取第一行汇编代码开始运行,bootloader先会初始化CPU,内存,网卡(如果需要),然后这部分的主要作用是把操作系统的kernel代码从硬盘加载到内存中,然后bootloader使命完成了,跳转到kernel的main函数入口开始执行kernel代码,kernel就是我们熟悉的Linux的内核代码了,大家说的看内核代码就是看的这个部分了,kernel代码启动以后,会重新初始化CPU,内存,网卡等设备,然后开始运行内核代码,最后,启动上帝进程(init),开始正常运行kernel,然后kernel会挂载文件系统。
好了,到这里,对进程来说都是无意义的,因为进程不关心这些,进程产生的时候这些工作已经做完了,进程能看到的就是这个文件系统了,对进程来说,内存空间,CPU核心数,网络资源,文件系统是他唯一能看得见使用得到的东西,所以我们的监狱环境就是这么几项核心的东西了。
kernel和文件系统是可以分离的,比如我们熟悉的ubuntu操作系统,可能用的是3.18的Linux Kernel,再加上一个自己的文件系统,也可以用2.6的Kernel加上同样的操作系统。每个Linux的发行版都是这样的,底层的Kernel可能都是同一个,不同的只是文件系统不同,所以,可以简单的认为,Linux的各种发行版就是kernel内核加上一个独特的文件系统,这个文件系统上有各种各样的工具软件。
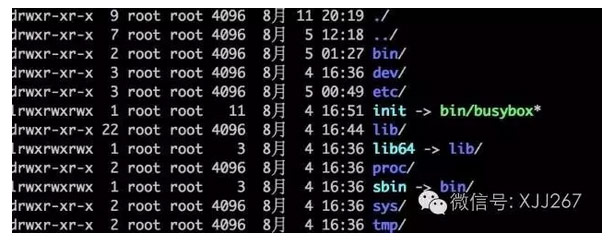
既然是这样,那么我们要软禁一个进程,最基础的当然要给他一个文件系统啦,文件系统简单的说就是一堆文件夹加上一堆文件组成的,我们先来生成一个文件系统,我之前是做嵌入式的,嵌入式的Linux系统生成文件系统一般用busybox,只需要在在ubuntu上执行下面的命令,就能生成一个文件系统:
apt-get install busybox-static
mkdir rootfs;cd rootfs
mkdir dev etc lib usr var proc tmp home root mnt sys
/bin/busybox –install -s bin
大概这么几步就制作完成了一个文件系统,也就是监狱的基本环境已经有了,记得把lib文件夹的内容拷过去。制作完了以后,文件系统就这样了。
还有一种方式,就是使用debootstap这个工具来做,也是几行命令就做完了一个debian的文件系统了,里面连apt-get都有,Docker的基础文件系统也是这个。
apt-get install qemu-user-static debootstrap binfmt-support
mkdir rootfs
debootstrap –foreign wheezy rootfs //wheezy是debian的版本
cp /usr/bin/qemu-arm-static rootfs/usr/bin/
完成以后,这个wheezy的文件系统就是一个标准的debian的文件系统了,里面的基本工具一应俱全。OK,基本的监狱环境已经搭建好了,进程住进去以后就跟在外面一样,啥都能干,但就是跑不出来。
要测试这个环境,可以使用Linux的chroot命令,chroot ./rootfs就进入了这个制作好的文件系统了,你可以试试,看不到外面的东西了哦。
打造探视系统【网络系统】
刚刚只建立了一个基本的监狱环境,对于现代的监狱,只有个房子不能上网怎么行?所以对于监狱环境,还需要建立一个网络环境,好让里面的进程们可以很方便的和监狱外的亲友们联系啊,不然谁愿意一个人呆在里面啊。
如何来建立一个网络呢?对于容器而言,很多地方是可配置的,这里说可配置,其实意思就是可配置也可以不配置,对于网络就是这样,一般的容器技术,对网络的支持有以下几个方式。
- 无网络模式,就是不配置模式了,不给他网络,只有文件系统,适合单机版的程序。
- 直接和宿主机使用同一套网络,也是不配置模式,但是这个不配置是不进行网络隔离,直接使用宿主机的网卡、ip、协议栈,这是最奔放的模式,各个容器如果启动的是同一套程序,那么需要配置不同的端口了,比如有3个容器,都是Redis程序,那么需要启动三个各不同的端口来提供服务,这样各个容器没有做到完全的隔离,但是这也有个好处,就是网络的吞吐量比较高,不用进行转发之类的操作。
- 网桥模式,也是Docker默认使用的模式,我们安装完Docker以后会多一个Docker0的网卡,其实这是一个网桥,一个网桥有两个端口,两个端口是两个不同的网络,可以对接两块网卡,从A网卡进去的数据会从B网卡出来,就像黑洞和白洞一样,我们建立好网桥以后,在容器内建一块虚拟网卡,把他和网桥对接,在容器外的宿主机上也建立一块虚拟网卡,和网桥对接,这样容器里面的进程就可以通过网桥这个探视系统和监狱外联系了。
我们可以直接使用第二种不配置模式,直接使用宿主机的网络,这也是最容易最方便的,但是我们在这里说的时候稍微说一下第三种的网桥模式吧。
网桥最开始的作用主要是用来连接两个不同的局域网的,更具体的应用,一般是用来连接两个不同的mac层的局域网的,比如有线电视网和以太网,一般网桥只做数据的过滤和转发,也可以适当的做一些限流的工作,没有路由器那么复杂,实现起来也比较简单,对高层协议透明,他能操作的都是mac报文,也就是在ip层以下的报文。
对于容器而言,使用网桥的方式是在宿主机上使用brctl命令建立一个网桥,作为容器和外界交互的渠道,也就是大家使用Docker的时候,用ifconfig命令看到的Docker0网卡,这实际上就是一个网桥,然后每启动一个容器,就用brctl命令建立一对虚拟网卡,一块给容器,一块连到网桥上。这样操作下来,容器中发给虚拟网卡的数据都会发给网桥,而网桥是宿主机上的,是能连接外网的,所以这样来做到了容器内的进程能访问外网。
容器的网络我没有深入研究,感觉不是特别复杂,最复杂的方式就是网桥的方式了,这些网络配置都可以通过命令行来进行,但是Docker的源码中是自己通过系统调用实现的,说实话我没怎么看明白,功力还是不够啊。我使用的就是最最简单的不隔离,和宿主机共用网卡,只能通过端口来区分不同容器中的服务。
监禁皮卡丘【隔离进程】
好了,监狱已经建好了,探视系统也有了,得抓人了来软禁了,把进程抓进来吧。我们以一个最最基本的进程/bin/bash为例,把这个进程抓进监狱吧。
说到抓进程,这时候就需要来聊聊容器的底层技术了,Linux提供几项基础技术来进行轻量级的系统隔离,这些个隔离技术组成了我们熟悉的Docker的基础。本篇不会大段的描述这些技术,文章后面我会给出一些参考链接,因为这类文章到处都可以找到,本篇只是让大家对容器本身有个了解。
下面所说的所有基础技术,其实就是一条系统调用,包括Docker的基础技术,也是这么一条系统调用(当然,Docker还有很多其他的,但是就容器来说,这条是核心的了)
clone(进程函数, 进程栈空间, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWNET |CLONE_NEWUSER | CLONE_NEWIPC , NULL
这是一条C语言的clone系统调用,实际上就是启动一个新的进程,后面的参数就是各种隔离了,包括UTS隔离、PID隔离、文件系统隔离、网络隔离、用户隔离、IPC通讯隔离。
在go语言中,没有clone这个系统调用(不知道为什么不做这个系统调用,可能是为了多平台的兼容吧),必须使用exec.Cmd这个对象来启动进程,在linux环境下,可以设置Cmd的attr属性,其中有个属性叫CloneFlags,可以把上面那些个隔离信息设置进去,这样,启动的进程就是我们需要的了,我们可以这么来启动这个进程。
cmd := exec.Command(“./container”, args…)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS | syscall.CLONE_NEWNET,
}
cmd.Run()
这样,通过这个cmd命令启动的./container进程就是一个隔离进程了,也就是我们把这个进程给关起来了,他已经看不到其他东西了,是不是很简单?但是你要是就直接这么运行,还是看不到什么特别的地方。
在这个之后,我们需要按照上面所说的,把监狱先建立好,监狱的建立在./container中进行,建立监狱也比较简单,基本上也是一堆系统调用,比如文件系统的软禁,就像下面的一样。
syscall.Mount(rootfs, tmpMountPoint, “”, syscall.MS_BIND, “”) //挂载根文件系统
syscall.Mount(rootfs+”/proc”, tmpMountPoint+”/proc”, “proc”, 0, “”); //挂载proc文件夹
syscall.PivotRoot(tmpMountPoint, pivotDir) //把进程软禁到根文件系统中
关于上面proc文件夹,做了特殊处理,在Linux中,proc文件夹的地位比较特殊,具体作用可以自行查文档,简单的说就是保存系统信息的文件夹。在这里,dev和sys这两个特殊文件夹也需要做特殊处理的,这里没有写出来而已。
这些都做完了以后,就可以启动真正需要执行的进程了,比如/bin/bash,或者你自己的程序,这样启动的/bin/bash或者你自己的程序就是在监狱中启动的了,那么他看到的所有东西都是监狱中的了,外面宿主机的一切对他来说都是屏蔽的了,这样,一个Docker的雏形就产生了。
这里多说一下,通过clone系统调用启动的进程,它自己看到自己的PID是1,也就是上帝进程了,这个上帝进程可以来造基础监狱【文件系统】,打造放风系统【网络系统】,然后再通过它来生成新的进程,这些进程出来就在监狱中了,我们使用Docker的时候,自己的服务实际上就是这些个在监狱中出生的进程【可能我的描述不太正确啊,我没有仔细看Docker的源码,我自己感觉是这样的】。
至此,我们来总结一下,启动一个最简单的容器并运行你自己的进程,需要几步。
- 建立一个监狱【文件系统】,使用busybox或者debootstrap建立。
- 建立一个放风系统【网络系统】,使用网桥或者不隔离网络,直接使用宿主机的网卡。
- 抓一个皮卡丘【启动上帝进程】并放到监狱中【挂载文件系统,初始化网络】,配置Cloneflags的值,并通过exec.Cmd来进行上帝进程的启动。
- 让皮卡丘生个孩子【启动你自己的程序】,直接调用exec.Cmd的run方法启动你自己的进程。
- 完成。
通过上面几步,最简容器就完成了,是不是很简单?但是容器仅仅有这些是不够的,我们还有三个隔离没有讲,这里稍微提一下吧。
- 一个是UTS隔离,主要是用来隔离hostname和域名的。
- 一个是User隔离,这样容器里面的用户和宿主机用户可以做映射,意思就是里面虽然看到的是root用户,但是实际上并不是root,不能够瞎搞系统,这样容器的安全性会有保障。
- 一个是IPC隔离,这个是进程通讯的隔离,这样容器里面的进程和容器外面的进程就不能进行进程间通讯了,保证了比较强的隔离性。
给犯人分配食物【资源配置】
我们知道,一般的监狱中的食物是定量的,毕竟不是每个监狱都可以吃自助餐的,容器也一样,要是我们就启个容器啥都不限制,里面要是有个牛逼的程序员写的牛逼程序,瞬间就把你的内存和CPU给干没了。比如像下面这个fork炸弹。【下面程序请不要尝试!!】
int main(){
while(fork());
}
在容器技术中,Cgroups【control groups】就是干这个事情的,cgroups负责给监狱设定资源,比如能用几个cpu啊,cpu能给你多少百分比的使用量啊,内存能用多少啊,磁盘能用多少啊,磁盘的速度能给你多少啊,各种资源都可以从cgroups来进行配置,把这些东西配置给容器以后,就算容器里面运行一个fork炸弹也不怕了,反正影响不到外面的宿主机,到这里,容器已经越来越像虚拟机了。
cgroups是linux内核提供的API,虽然是API,但它的整个实现完美满足了Linux两大设计哲学之一:一切皆文件(还有一个哲学是通讯全管道),对API的调用实际上是操作文件。
我们以cpu的核心数看看如何来做一个cgroups的资源管理。假设我们的物理机是个8核的cpu,而我们刚刚启动的容器我只想让他使用其中的两个核,很简单,我们用命令行直接操作sys/fs/cgroups文件夹下的文件来进行。这个配置我们可以在启动的上帝进程中进行,也可以在容器外部进行,都是直接操作文件。
关于cgroups这个东西很复杂也很强大,其实在容器出来之前,好的运维工程师就已经把这个玩得很溜了。Docker也只是把这些个文件操作封装了一下,变成了docker的启动和配置参数而已。
亲自抓一次进程吧
好了,该说的都说了,我们来实战一把,自己启一个容器吧,并且启动以后为了更直观的看到效果,我们启动一个ssh服务,打开22332端口,然后外面就可以通过ssh连到容器内部了,这时候你爱干什么干什么了。
制作文件系统
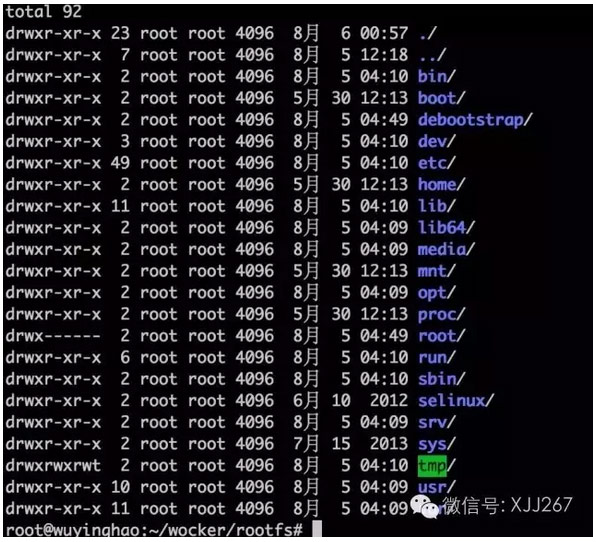
文件系统制作我们直接使用debootstrap进行制作,在/root/目录下建立一个rootfs的文件夹,然后使用debootstrap –foreign wheezy rootfs制作文件系统,制作完了以后,文件系统就是下面这个样子
制作初始化脚本
初始化脚本就做两件事情,一是启动ssh服务,一是启动一个shell,提前先把/etc/ssh/sshd_config中的端口改成23322。
#!/bin/bash
service ssh start
/bin/bash
然后把这个脚本放到制作的文件系统的root目录下,加上执行权限。
启动上帝进程
文件系统制作完成了,启动脚本也做完了,我们看看我们这个容器的架构,架构很简单,整个容器分为两个独立的进程,两份独立的代码。
- 一个是主进程【wocker.go】,这个进程本身就是一个http的服务,通过get方法接收参数,参数有rootfs的地址,容器的hostname,需要监禁的进程名称(这里就是我们的第二个进程【startContainer.go】),然后通过exec.Cmd这个包启动这个进程。
- 第二个进程启动就是以隔离方式启动的了,就是容器的上帝进程了,这个进程中进行文件系统挂载,hostname设置,权限系统的设定,然后启动正式的服务进程(也就是我们的启动脚本/root/start_container.sh)
挂载文件系统
第二个进程是容器的上帝进程,在这里进行文件系统的挂载,最重要的代码如下
syscall.Mount(rootfs, tmpMountPoint, “”, syscall.MS_BIND, “”) //挂载根文件系统
syscall.Mount(procpath, tmpMountPointProc, “proc”, 0, “”) //挂载proc文件夹,用来看系统信息的
syscall.Mount(syspath, tmpMountPointSys, “sysfs”, 0, “”) //挂载sys文件夹,用来做权限控制的
syscall.Mount(“udev”, tmpMountPointDev, “devtmpfs”, 0, “”) //挂载dev,用来使用设备的
syscall.PivotRoot(tmpMountPoint, pivotDir)//进入到文件系统中
具体代码可以看github上的文件,这样,根文件系统就挂载完了,已经进入了基本监狱中了。
启动初始化脚本
文件系统挂载完了以后,然后启动初始化脚本,这个就比较简单了,一个exec.Cmd的Run方法调用就搞定了。
cmd := exec.Command(“/root/start_container.sh”)
这样,ssh服务就在容器中启动了,可以看到一行Starting OpenBSD Secure Shell server: sshd.的打印信息,容器启动完成,这时候,我们可以通过ssh root@127.0.0.1 -p 23322这个命令登录进我们的容器了,然后你就可以为所欲为了。
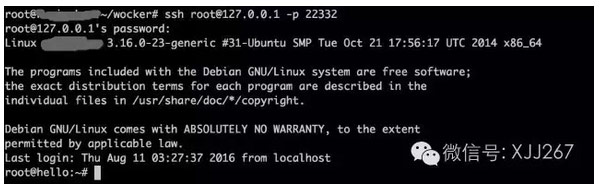
上面那个图,我们看到登录进来以后,hostname已经显示为我们设定的hello了,这时这个会话已经在容器里面了,我们ps一下看看进程们。
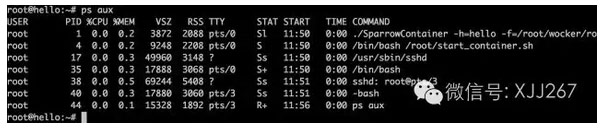
看到pid为1的进程了么,那个就是启动这个容器的上帝进程了。恩,到这里,我们已经在容器中了,这里启动的任何东西都和我们知道的Docker中的进程没什么太大区别了。但在这里,我缺失了权限的部分,大家可以自己加上去,主要是各种文件操作比较麻烦……
关于Docker的思考
Docker这门最近两年非常火的技术,光从容器的角度来看的话,也不算什么新的牛逼技术了,和虚拟机比起来还是要简单不少,当然,Docker本身可完全不止容器技术本身,还有AUFS文件分层技术,还有etcd集群技术,最关键的是Docker通过自己的整个生态把容器包裹在里面了,提供了一整套的容器管理套件,这样让容器的使用变得异常简单,所以Docker才能这么流行吧。和虚拟机比起来,Docker的优点实在是太多了。
- 首先,从易用性的角度来说,管理一个虚拟机的集群,有一整套软件系统,比如openstack这种,光熟悉这个openstack就够喝一壶的了,而且openstack的网络管理异常复杂,哦,不对,是变态级的复杂,要把网络调通不是那么容易的事情。
- 第二,从性能上来看看,我们刚刚说了容器的原理,所以实际上容器不管是对cpu的利用,还是内存的操作或者外部设备的操作,对一切硬件的操作实际上都是直接操作的,并没有经过一个中间层进行过度,但是虚拟机就不一样了,虚拟机是先操作假的硬件,然后假硬件再操作真硬件,利用率从理论上就会比容器的要差,虽然现在有硬件虚拟化的技术了能提升一部分性能,但从理论上来说性能还是没有容器好,这部分我没有实际测试过啊,只是从理论上这么觉得的,如果有不对的欢迎拍砖啊。
- 第三,从部署的易用性上和启动时间上,容器就完全可以秒了虚拟机了,这个不用多说吧,一个是启动一台假电脑,一个是启动一个进程。
那么,Docker和虚拟机比起来,缺点在哪里呢?我自己想了半天,除了资源隔离性没有虚拟机好以外,我实在是想不出还有什么缺点,因为cgroups的隔离技术只能设定一个上限,比如在一台4核4G的机器上,你可能启动两个Docker,给他们的资源都是4核4G,如果有个Docker跑偏了,一个人就干掉了4G内存,那么另外一个Docker可能申请不到资源了。
而虚拟机就不存在这个问题,但是这也是个双刃剑,Docker的这种做法可以更多的榨干系统资源,而虚拟机的做法很可能在浪费系统资源。除了这个,我实在是想不出还有其他缺点。网上也有说权限管理没有虚拟机好,但我觉得权限这东西,还是得靠人,靠软件永远靠不住。
最后,代码都在github上,只有非常非常简单的三个文件【一个Container.go是容器类,一个wocker.go没内容,一个startContainer.go启动容器】,那个http服务留着没写,后面写http服务的时候在用一下。嗯,Docker确实是个好东西。
参考链接:
rootfs:https://olimex.wordpress.com/2014/07/21/how-to-create-bare-minimum-debian-wheezy-rootfs-from-scratch/
Cgroups:http://tech.meituan.com/cgroups.html
namespace:http://man7.org/linux/man-pages/man7/namespaces.7.html作者:西加加语言 订阅号(ID:XJJ267)吴坚

好厉害[/钱]